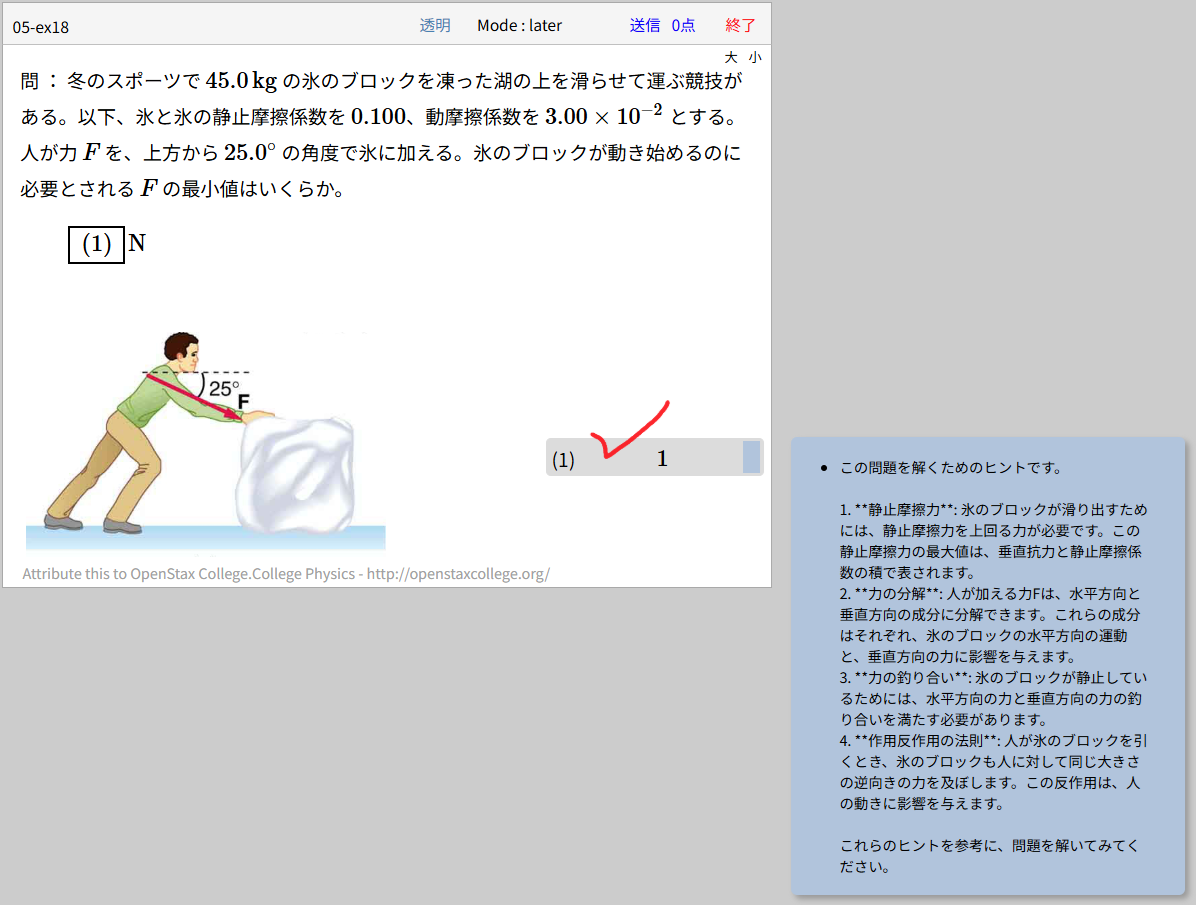
上の図は e-Learning 教材のキャプチャーですが,gemma3:12b に,問題文を画像としたものを読み込ませて,解答のヒントを出すように依頼したものです。画像(png)の内容を読み取って,適当なヒントを返しています。ヒントの内容はあらかじめ用意したものではありません。受講生が解答を送信する際に毎回新たに作成されます。解答を再送してみます。

多少長くなって,文章が変化しています。言語モデルへの依頼は下記のようなものです。
response = ollama.chat(
model='gemma3:12b',
messages=[{
'role': 'user',
'content': '画像は物理の練習問題です。問いを解くためのヒントを教えてください。正解は教えないでください。',
'images': ['/var/www/html/temporary/' + foldername + '/simple_question/cutycapt.png']
}]
)コードにある cutycapt.png というファイルが問題文のキャプチャー画像です。教材は SCORM コンテンツなのですが,その教材を作る際に問題文のキャプチャー画像を含めるようにしました。キャプチャー画像や正解と回答が,LMSが動いているコンピューターとは別の採点サーバーに送られます。そのサーバー上にテンポラリーフォルダーを確保し,キャプチャー画像を書き出しています。
採点が重なると上手く処理できません。ビデオカードの計算機能を利用するのですが,リクエストが同時に来ると,処理能力が不足します。(限度もありますが)幾つかのリクエストが重なっても対応できるように,数台のパソコンを利用したシステムを構築したいと考えています。