
NVLinkを利用し,ビデオカードを2枚刺して計算してみたい。以下,主なパーツをあげます。
(20200918 結局今のところ NVLink は上手く利用できていません。)
- CPU : Core i5 9500
- MB : ASRock Z390 Extreme4
- GPU : RTX 2070 Super X 2 (ASUS DUAL-RTX2070S-O8G-EVO)
- NVLink : ASUS ROG-NVLINK-3
- Case : SilverStone SST-RM400
- 電源 : Seasonic SSR-850FX
あまりにも2枚のカードの間に隙間が無かったので,ビデオカードのカバーを片方外しました。ケースファンの風を直接あてて冷却を補助しています。

他の角度のものもあげます。



下記のサイトに従って作業した。
とくに今のところ NVLink に対応した作業が無い。色々なコマンドの応答からは2枚とも認識されていることは分かるが,NVLink が機能していることを確かめるにはどうしたら良いのか?
温度をモニターしたいと思って,Psensor というソフトをインストールした。
下図が計算中の観測。温度上昇にやや遅れて,ファンの回転数が上昇している。計測できるのは,ビデオカードの温度,ファンの回転数,メモリーの使用状況などである。
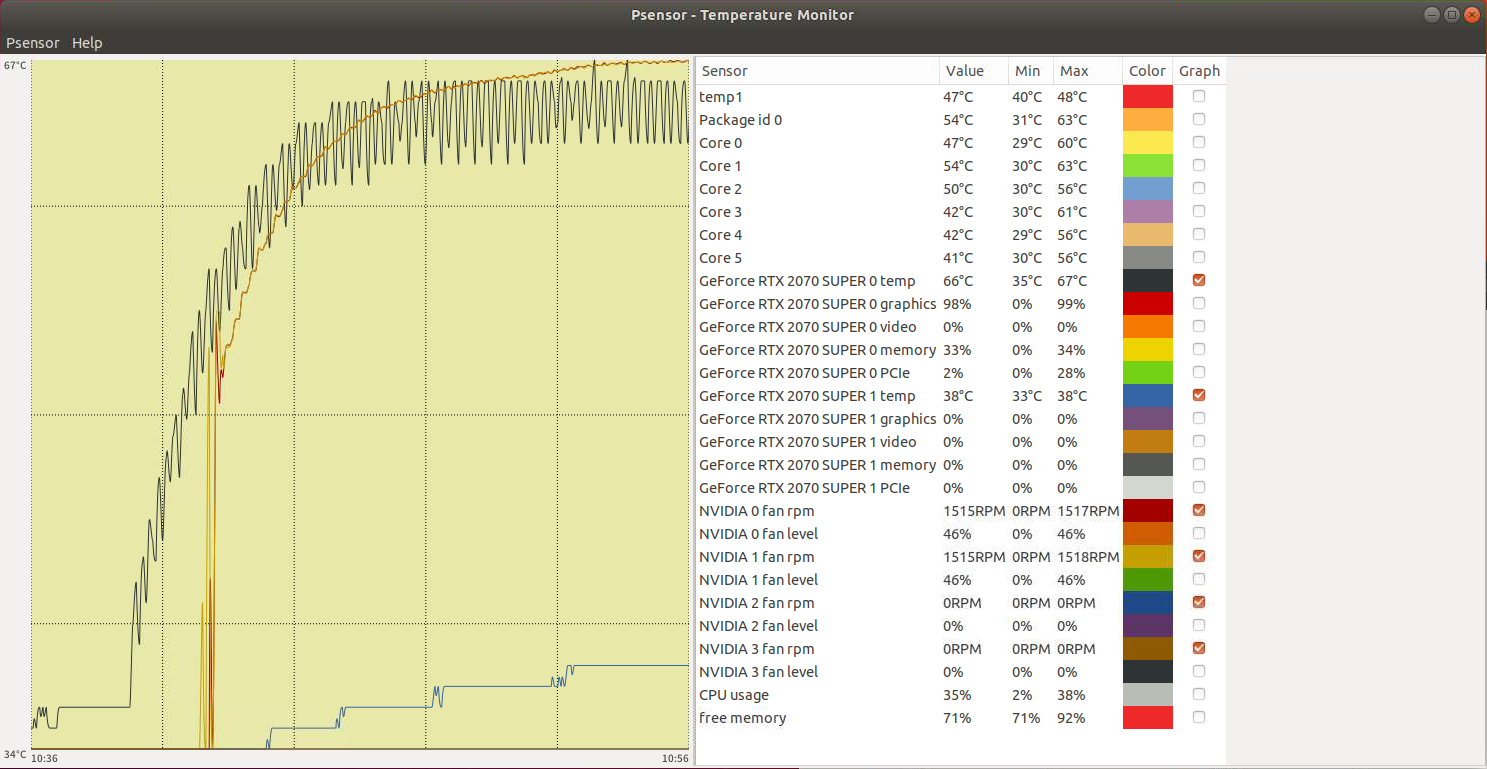
メモリーや温度の上昇から見て,2枚目のビデオカードは利用されていない。もう少し大きな計算をやってみた方がよさそう。上記の計算は CUPY を利用したものである。NVLink が機能することと CUPY がNVLink 上で利用可能となるまでにはかなり隔たりがあるのかもしれない。
(20200803)
NVLink に関する応答メッセージを見つけた。dmesg | grep -i nvidia への応答の中に nvidia-nvlink: Nvlink Core is being initialized とある。
dmesg | grep -i nvidia
[ 2.872886] nvidia: loading out-of-tree module taints kernel.
[ 2.872892] nvidia: module license 'NVIDIA' taints kernel.
[ 2.876488] nvidia: module verification failed: signature and/or required key missing - tainting kernel
[ 2.882683] nvidia-nvlink: Nvlink Core is being initialized, major device number 239
[ 2.883223] nvidia 0000:01:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=io+mem
[ 2.927112] nvidia 0000:02:00.0: enabling device (0000 -> 0003)
[ 2.927191] nvidia 0000:02:00.0: vgaarb: changed VGA decodes: olddecodes=io+mem,decodes=none:owns=none
[ 2.976932] NVRM: loading NVIDIA UNIX x86_64 Kernel Module 450.51.06 Sun Jul 19 20:02:54 UTC 2020
[ 2.998138] nvidia-modeset: Loading NVIDIA Kernel Mode Setting Driver for UNIX platforms 450.51.06 Sun Jul 19 20:06:42 UTC 2020
[ 2.999991] [drm] [nvidia-drm] [GPU ID 0x00000100] Loading driver
[ 2.999992] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:01:00.0 on minor 0
[ 3.000411] [drm] [nvidia-drm] [GPU ID 0x00000200] Loading driver
[ 3.000412] [drm] Initialized nvidia-drm 0.0.0 20160202 for 0000:02:00.0 on minor 1
[ 3.012872] nvidia-uvm: Loaded the UVM driver, major device number 236.
[ 3.436405] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:00/0000:00:01.1/0000:02:00.1/sound/card2/input15
[ 3.436444] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:00/0000:00:01.1/0000:02:00.1/sound/card2/input17
[ 3.436506] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:00/0000:00:01.1/0000:02:00.1/sound/card2/input19
[ 3.436544] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:00/0000:00:01.1/0000:02:00.1/sound/card2/input21
[ 3.436638] input: HDA NVidia HDMI/DP,pcm=3 as /devices/pci0000:00/0000:00:01.0/0000:01:00.1/sound/card1/input14
[ 3.436663] input: HDA NVidia HDMI/DP,pcm=7 as /devices/pci0000:00/0000:00:01.0/0000:01:00.1/sound/card1/input16
[ 3.436691] input: HDA NVidia HDMI/DP,pcm=8 as /devices/pci0000:00/0000:00:01.0/0000:01:00.1/sound/card1/input18
[ 3.436718] input: HDA NVidia HDMI/DP,pcm=9 as /devices/pci0000:00/0000:00:01.0/0000:01:00.1/sound/card1/input20
[10301.646637] nvidia-modeset: WARNING: GPU:0: Unable to read EDID for display device Eizo EV2736W (HDMI-0)上手く行っているのだろうか?nvidia-smi nvlink -c の出力は下記のような感じ。
nvidia-smi nvlink -c
GPU 0: GeForce RTX 2070 SUPER (UUID: GPU-34242219-6f19-24de-f016-787c4f3cb2d0)
Link 0, P2P is supported: true
Link 0, Access to system memory supported: true
Link 0, P2P atomics supported: true
Link 0, System memory atomics supported: true
Link 0, SLI is supported: true
Link 0, Link is supported: false
GPU 1: GeForce RTX 2070 SUPER (UUID: GPU-aed31587-58ba-52cc-a909-6906c3635b30)
Link 0, P2P is supported: true
Link 0, Access to system memory supported: true
Link 0, P2P atomics supported: true
Link 0, System memory atomics supported: true
Link 0, SLI is supported: true
Link 0, Link is supported: falsenvidia-smi nvlink -s の出力は下記。
nvidia-smi nvlink -s
GPU 0: GeForce RTX 2070 SUPER (UUID: GPU-34242219-6f19-24de-f016-787c4f3cb2d0)
Link 0: 25.781 GB/s
GPU 1: GeForce RTX 2070 SUPER (UUID: GPU-aed31587-58ba-52cc-a909-6906c3635b30)
Link 0: 25.781 GB/s
CUDA サンプルを試してみる。サンプルのコンパイルをやって,端末から起動する。下図は nbody というサンプル。ファイルをダブルクリックでは動かない。ライブラリーがないとか怒られる。

メモリーをほとんど使用しない。これで 1 % ぐらいだ。このデモでは,温度が急上昇する。85度ぐらいまで一気に上がる。少し怖くなって,どこまで上昇するかは試さなかった。デモを止めると急降下する。
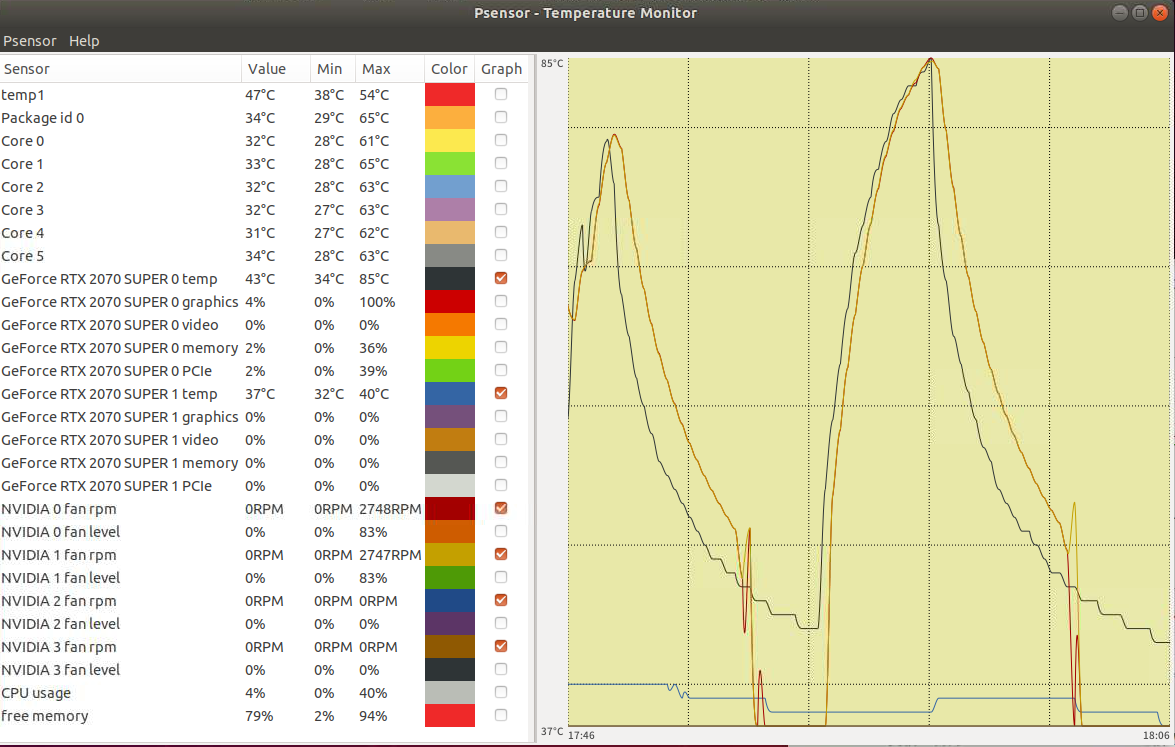
2つのビデオカードを使用して実行するように、オプションをつけて nbody -numdevices=2 としてみた。2000 GFLOP/S 程度だったのが、4000 GFLOP/S あたりに倍増している。
両方の GPU の温度が上昇している。2つのビデオカードの温度に差がありすぎる。

(20200804)
ビデオカードのカバーを再び付けてみた。二つのカードの温度の開きは20度ぐらい。最高温度は85度だった。こちらにするべきか?
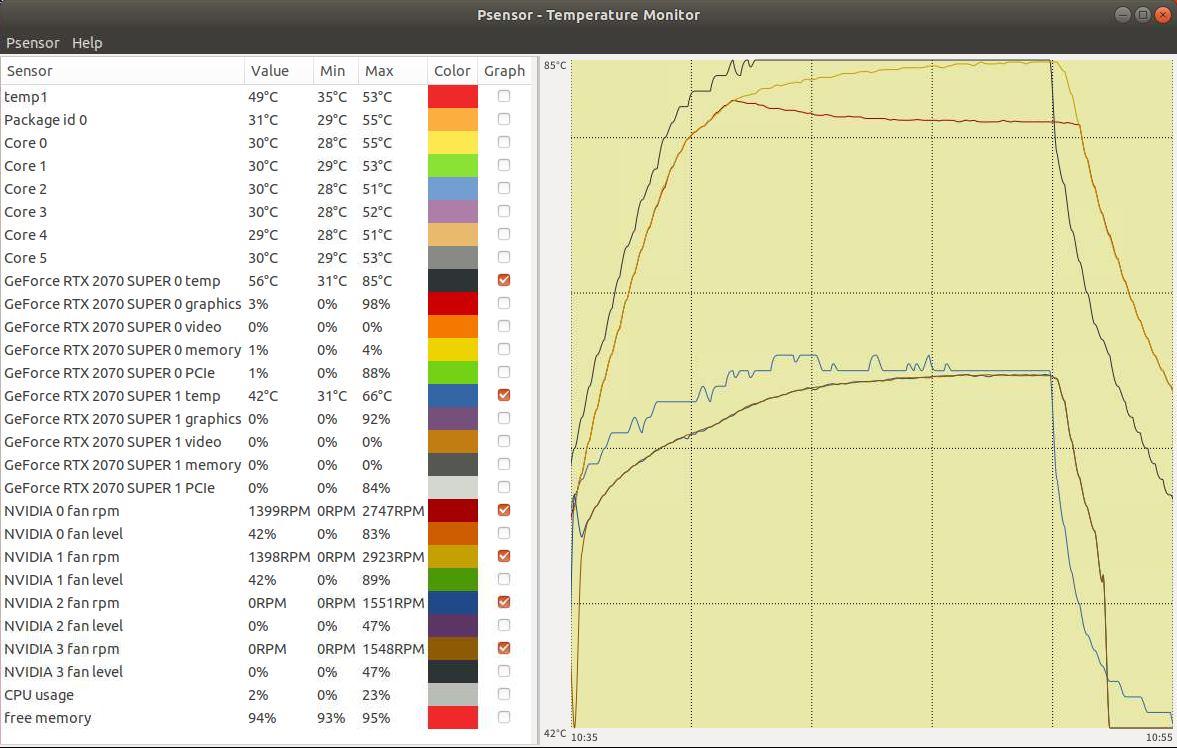
同じ条件で,カバー無しの方を計測してみたら,最高温度が82度だった。当初の計画通りカバー無しの方で行くことにする。
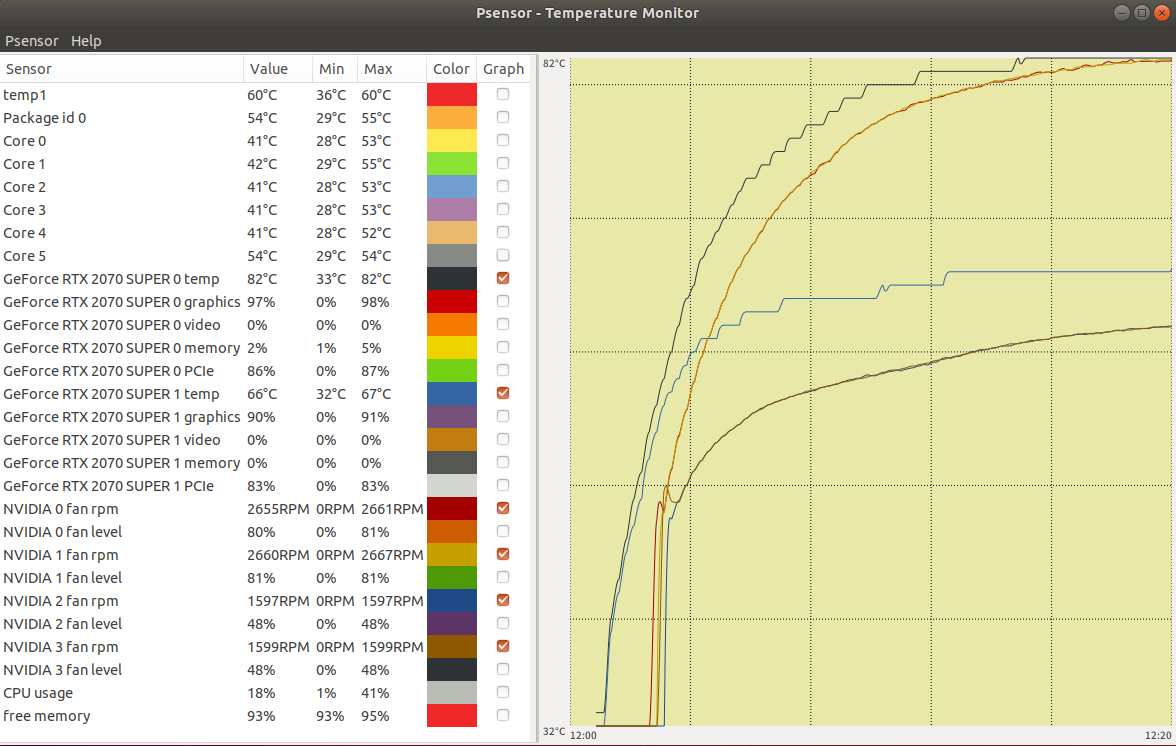
後日,外気を取り込むケースファンのフィルターを外して,風量をあげてみたら 78 度まで温度が下がった。これぐらいなら大丈夫かな?
下記のサイトにしたがって、いくらか確認してみた。
参考サイト:NVLINK on RTX 2080 TensorFlow and Peer-to-Peer Performance with Linux
CUDA サンプルにある simpleP2P を実行してみた。
./simpleP2P
[./simpleP2P] - Starting...
Checking for multiple GPUs...
CUDA-capable device count: 2
Checking GPU(s) for support of peer to peer memory access...
> Peer access from GeForce RTX 2070 SUPER (GPU0) -> GeForce RTX 2070 SUPER (GPU1) : Yes
> Peer access from GeForce RTX 2070 SUPER (GPU1) -> GeForce RTX 2070 SUPER (GPU0) : Yes
Enabling peer access between GPU0 and GPU1...
Allocating buffers (64MB on GPU0, GPU1 and CPU Host)...
Creating event handles...
cudaMemcpyPeer / cudaMemcpy between GPU0 and GPU1: 22.53GB/s
Preparing host buffer and memcpy to GPU0...
Run kernel on GPU1, taking source data from GPU0 and writing to GPU1...
Run kernel on GPU0, taking source data from GPU1 and writing to GPU0...
Copy data back to host from GPU0 and verify results...
Disabling peer access...
Shutting down...
Test passedCUDA サンプルにある p2pBandwidthLatencyTest を実行してみた。
./p2pBandwidthLatencyTest
[P2P (Peer-to-Peer) GPU Bandwidth Latency Test]
Device: 0, GeForce RTX 2070 SUPER, pciBusID: 1, pciDeviceID: 0, pciDomainID:0
Device: 1, GeForce RTX 2070 SUPER, pciBusID: 2, pciDeviceID: 0, pciDomainID:0
Device=0 CAN Access Peer Device=1
Device=1 CAN Access Peer Device=0
***NOTE: In case a device doesn't have P2P access to other one, it falls back to normal memcopy procedure.
So you can see lesser Bandwidth (GB/s) and unstable Latency (us) in those cases.
P2P Connectivity Matrix
D\D 0 1
0 1 1
1 1 1
Unidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1
0 377.78 6.09
1 6.10 388.04
Unidirectional P2P=Enabled Bandwidth (P2P Writes) Matrix (GB/s)
D\D 0 1
0 388.37 24.23
1 24.23 387.52
Bidirectional P2P=Disabled Bandwidth Matrix (GB/s)
D\D 0 1
0 385.93 9.21
1 9.21 384.11
Bidirectional P2P=Enabled Bandwidth Matrix (GB/s)
D\D 0 1
0 387.50 48.38
1 48.07 383.19
P2P=Disabled Latency Matrix (us)
GPU 0 1
0 1.21 13.10
1 13.15 1.23
CPU 0 1
0 1.99 5.23
1 5.22 1.92
P2P=Enabled Latency (P2P Writes) Matrix (us)
GPU 0 1
0 1.20 0.75
1 0.70 1.24
CPU 0 1
0 1.95 1.68
1 1.82 2.09
NOTE: The CUDA Samples are not meant for performance measurements. Results may vary when GPU Boost is enabled.(20200806)
CUPY のマニュアルを読んでいると、GPU を切り替えるというコマンドがあった。
# coding: utf-8
import sys, os
import numpy as np
import cupy as cp
cp.cuda.Device(1).use()上記の最後のコードで使用する GPU を切り替える。そうすると確かに2番めの GPU で計算し始めたようで、2番めのビデオカードの温度が上昇した。
(20200810)
https://www.v-t.co.jp/product/gpuphi/nvlink/には下記のようにある。
- Quadro(RTX/GP/GV)シリーズの2つの GPUを、NVLinkを用いたNVLink Bridgeで接続することにより、従来のPCIeバス間の通信よりも高速に通信することが可能です。対応したアプリケーションを利用すれば、マルチGPU 構成でメモリとパフォーマンスを簡単に拡張できます。
例えば、2つのQuadro RTX 8000をQuadro RTX 8000 NVLink HB ブリッジで接続し、最大毎秒 100 GB の帯域幅、及び合計96GBのGDDR6 メモリとして、大規模なレンダリング、AI、バーチャル リアリティ、ビジュアライゼーションのワークロードに対応できます。
ただしGeForce RTX 20シリーズ(2060は未対応)では、接続インターフェイスとしての利用に留まり、メモリやCUDAコアを統合して扱うことはできませんが、P2PでのGPU間のデータ転送は高速化されます。一方で、ソフトウェア的な互換性は維持されているため、「SLI」対応アプリケーションは「NVLink SLI」でもそのまま使用することができます。
これからすると,私のレベルでは NVLink の恩恵にはあずかれそうにない。先にあげたリンク先
ここに記述されている内容に期待するぐらいだろうか。
(20200814)
『scikit-learnとTensorFlowによる実践機械学習』という本が手元に在って,先にあげたリンクが tensorflow でベンチマークを取っていたので,少し読んでみることにした。しかし本の記述通りにはサンプルコードが動かない。12章にGPU対応の tensorflow をインストールする話が在って,そこの記述に従ってやってみたが sess = tf.Session() でエラーとなる。調べてみると tensorflow はバージョン2で色々と変化があったようで,session は使わなくなったようだ。インストールしたソフトのバージョンを調べたら,CUDA が 11 で,tensorflow が 2.3 だった。この本は原書では次の版が出ていたが,日本語訳はまだである。第2版のサイトにはまだサンプルコードが載せられていない。きっと内容は tensorflow2 に対応したものになっていると思うのだが。
CUDA 10.1 のマシンが在って,そちらに tensorflow 1.4 を入れてみると本のコードが動いた。ただし gpu 無しの tensorflow の場合である。バージョンを指定したインストール方法は,このサイトを参考にした。コマンドを記録する。
pip3 install tensorflow==1.4tensorflow を動かしながら,『scikit-learnとTensorFlowによる実践機械学習』の9章を読んでみた。
(20200818)
下記の記事を多少読んでみた。tensorflow のバージョンは 1.5 である。docker 関連の情報がある。
- 参考サイト:TensorFlow入門
この先,docker を使って NVLink の効果を試すことになりそう。
(20200821)
下記の記事を読む。
(20200824)
アプライドのサイト「TensorFlow ベンチーマークテスト(1)GeFoce 2080Ti」にある内容を試してみた。
ベンチマークのダウンロードをする。
git clone https://github.com/tensorflow/benchmarks.gitその中にあるファイル benchmarks/scripts/tf_cnn_benchmarks/tf_cnn_benchmarks.py がターゲットである。
隔離された環境(tensorflow 2.3)で、上記のスクリプトを実行した。下記は、gpu を2つ利用した場合である。コマンドは同じフォルダーにある READEME.md に記してあったもの。
(env) friend@z390:~/benchmarks/scripts/tf_cnn_benchmarks$ python3 ./tf_cnn_benchmarks.py --num_gpus=2 --batch_size=32 --model=resnet50 --variable_update=parameter_server
2020-08-24 17:18:43.949784: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
WARNING:tensorflow:From /home/friend/ml_gpu/env/lib/python3.6/site-packages/tensorflow/python/compat/v2_compat.py:96: disable_resource_variables (from tensorflow.python.ops.variable_scope) is deprecated and will be removed in a future version.
Instructions for updating:
non-resource variables are not supported in the long term
2020-08-24 17:18:44.925432: I tensorflow/core/platform/cpu_feature_guard.cc:142] This TensorFlow binary is optimized with oneAPI Deep Neural Network Library (oneDNN)to use the following CPU instructions in performance-critical operations: AVX2 FMA
To enable them in other operations, rebuild TensorFlow with the appropriate compiler flags.
2020-08-24 17:18:44.950146: I tensorflow/core/platform/profile_utils/cpu_utils.cc:104] CPU Frequency: 3000000000 Hz
2020-08-24 17:18:44.950385: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x45bfaf0 initialized for platform Host (this does not guarantee that XLA will be used). Devices:
2020-08-24 17:18:44.950404: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): Host, Default Version
2020-08-24 17:18:44.952309: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcuda.so.1
2020-08-24 17:18:45.105237: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.113618: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.114043: I tensorflow/compiler/xla/service/service.cc:168] XLA service 0x45be170 initialized for platform CUDA (this does not guarantee that XLA will be used). Devices:
2020-08-24 17:18:45.114056: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (0): GeForce RTX 2070 SUPER, Compute Capability 7.5
2020-08-24 17:18:45.114061: I tensorflow/compiler/xla/service/service.cc:176] StreamExecutor device (1): GeForce RTX 2070 SUPER, Compute Capability 7.5
2020-08-24 17:18:45.114440: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.114778: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2070 SUPER computeCapability: 7.5
coreClock: 1.815GHz coreCount: 40 deviceMemorySize: 7.79GiB deviceMemoryBandwidth: 417.29GiB/s
2020-08-24 17:18:45.114824: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.115147: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 1 with properties:
pciBusID: 0000:02:00.0 name: GeForce RTX 2070 SUPER computeCapability: 7.5
coreClock: 1.815GHz coreCount: 40 deviceMemorySize: 7.79GiB deviceMemoryBandwidth: 417.29GiB/s
2020-08-24 17:18:45.115168: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-08-24 17:18:45.116255: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-08-24 17:18:45.117360: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-08-24 17:18:45.117600: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-08-24 17:18:45.118782: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-08-24 17:18:45.119464: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-08-24 17:18:45.121877: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-08-24 17:18:45.121976: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.122365: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.122712: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.123049: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.123361: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0, 1
2020-08-24 17:18:45.123385: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-08-24 17:18:45.737310: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-08-24 17:18:45.737361: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0 1
2020-08-24 17:18:45.737368: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N Y
2020-08-24 17:18:45.737374: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 1: Y N
2020-08-24 17:18:45.737571: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.738093: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.738478: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.738843: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7023 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-08-24 17:18:45.739364: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:45.739713: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 7269 MB memory) -> physical GPU (device: 1, name: GeForce RTX 2070 SUPER, pci bus id: 0000:02:00.0, compute capability: 7.5)
TensorFlow: 2.3
Model: resnet50
Dataset: imagenet (synthetic)
Mode: training
SingleSess: False
Batch size: 64 global
32 per device
Num batches: 100
Num epochs: 0.00
Devices: ['/gpu:0', '/gpu:1']
NUMA bind: False
Data format: NCHW
Optimizer: sgd
Variables: parameter_server
==========
Generating training model
WARNING:tensorflow:From /home/friend/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:134: conv2d (from tensorflow.python.keras.legacy_tf_layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv2D` instead.
W0824 17:18:45.750814 139659219543872 deprecation.py:323] From /home/friend/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:134: conv2d (from tensorflow.python.keras.legacy_tf_layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use `tf.keras.layers.Conv2D` instead.
WARNING:tensorflow:From /home/friend/ml_gpu/env/lib/python3.6/site-packages/tensorflow/python/keras/legacy_tf_layers/convolutional.py:424: Layer.apply (from tensorflow.python.keras.engine.base_layer_v1) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `layer.__call__` method instead.
W0824 17:18:45.754501 139659219543872 deprecation.py:323] From /home/friend/ml_gpu/env/lib/python3.6/site-packages/tensorflow/python/keras/legacy_tf_layers/convolutional.py:424: Layer.apply (from tensorflow.python.keras.engine.base_layer_v1) is deprecated and will be removed in a future version.
Instructions for updating:
Please use `layer.__call__` method instead.
WARNING:tensorflow:From /home/friend/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:266: max_pooling2d (from tensorflow.python.keras.legacy_tf_layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.MaxPooling2D instead.
W0824 17:18:45.776025 139659219543872 deprecation.py:323] From /home/friend/benchmarks/scripts/tf_cnn_benchmarks/convnet_builder.py:266: max_pooling2d (from tensorflow.python.keras.legacy_tf_layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.MaxPooling2D instead.
Initializing graph
WARNING:tensorflow:From /home/friend/benchmarks/scripts/tf_cnn_benchmarks/benchmark_cnn.py:2268: Supervisor.__init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.MonitoredTrainingSession
W0824 17:18:48.420785 139659219543872 deprecation.py:323] From /home/friend/benchmarks/scripts/tf_cnn_benchmarks/benchmark_cnn.py:2268: Supervisor.__init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.MonitoredTrainingSession
2020-08-24 17:18:48.689375: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.689736: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 0 with properties:
pciBusID: 0000:01:00.0 name: GeForce RTX 2070 SUPER computeCapability: 7.5
coreClock: 1.815GHz coreCount: 40 deviceMemorySize: 7.79GiB deviceMemoryBandwidth: 417.29GiB/s
2020-08-24 17:18:48.689798: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.690118: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1716] Found device 1 with properties:
pciBusID: 0000:02:00.0 name: GeForce RTX 2070 SUPER computeCapability: 7.5
coreClock: 1.815GHz coreCount: 40 deviceMemorySize: 7.79GiB deviceMemoryBandwidth: 417.29GiB/s
2020-08-24 17:18:48.690139: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudart.so.10.1
2020-08-24 17:18:48.690155: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-08-24 17:18:48.690165: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcufft.so.10
2020-08-24 17:18:48.690175: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcurand.so.10
2020-08-24 17:18:48.690184: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusolver.so.10
2020-08-24 17:18:48.690193: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcusparse.so.10
2020-08-24 17:18:48.690202: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
2020-08-24 17:18:48.690237: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.690566: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.690896: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.691223: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.691566: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1858] Adding visible gpu devices: 0, 1
2020-08-24 17:18:48.691616: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1257] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-08-24 17:18:48.691637: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1263] 0 1
2020-08-24 17:18:48.691641: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 0: N Y
2020-08-24 17:18:48.691645: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1276] 1: Y N
2020-08-24 17:18:48.691757: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.692168: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.692665: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.693011: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7023 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-08-24 17:18:48.693165: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:982] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-08-24 17:18:48.693480: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1402] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 7269 MB memory) -> physical GPU (device: 1, name: GeForce RTX 2070 SUPER, pci bus id: 0000:02:00.0, compute capability: 7.5)
INFO:tensorflow:Running local_init_op.
I0824 17:18:50.304418 139659219543872 session_manager.py:505] Running local_init_op.
INFO:tensorflow:Done running local_init_op.
I0824 17:18:50.338307 139659219543872 session_manager.py:508] Done running local_init_op.
Running warm up
2020-08-24 17:18:51.596903: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcublas.so.10
2020-08-24 17:18:51.931339: I tensorflow/stream_executor/platform/default/dso_loader.cc:48] Successfully opened dynamic library libcudnn.so.7
Done warm up
Step Img/sec total_loss
1 images/sec: 367.7 +/- 0.0 (jitter = 0.0) 7.829
10 images/sec: 384.5 +/- 4.4 (jitter = 12.5) 8.001
20 images/sec: 379.3 +/- 4.2 (jitter = 13.3) 7.946
30 images/sec: 381.3 +/- 3.4 (jitter = 8.0) 7.869
40 images/sec: 378.8 +/- 3.1 (jitter = 14.3) 7.727
50 images/sec: 378.4 +/- 2.8 (jitter = 14.8) 7.751
60 images/sec: 377.6 +/- 2.6 (jitter = 24.8) 7.933
70 images/sec: 376.3 +/- 2.4 (jitter = 29.1) 7.915
80 images/sec: 375.5 +/- 2.3 (jitter = 28.1) 7.894
90 images/sec: 374.7 +/- 2.1 (jitter = 23.9) 7.830
100 images/sec: 374.5 +/- 2.0 (jitter = 23.9) 8.156
----------------------------------------------------------------
total images/sec: 374.28
----------------------------------------------------------------
(env) friend@z390:~/benchmarks/scripts/tf_cnn_benchmarks$ 温度上昇とメモリーの使用率は下図。メモリーは両方の gpu とも 70% ぐらいだった。温度が下がるのには時間がかかっている。メモリーの使用率が下がったところあたりが計算の終了時刻を示している。
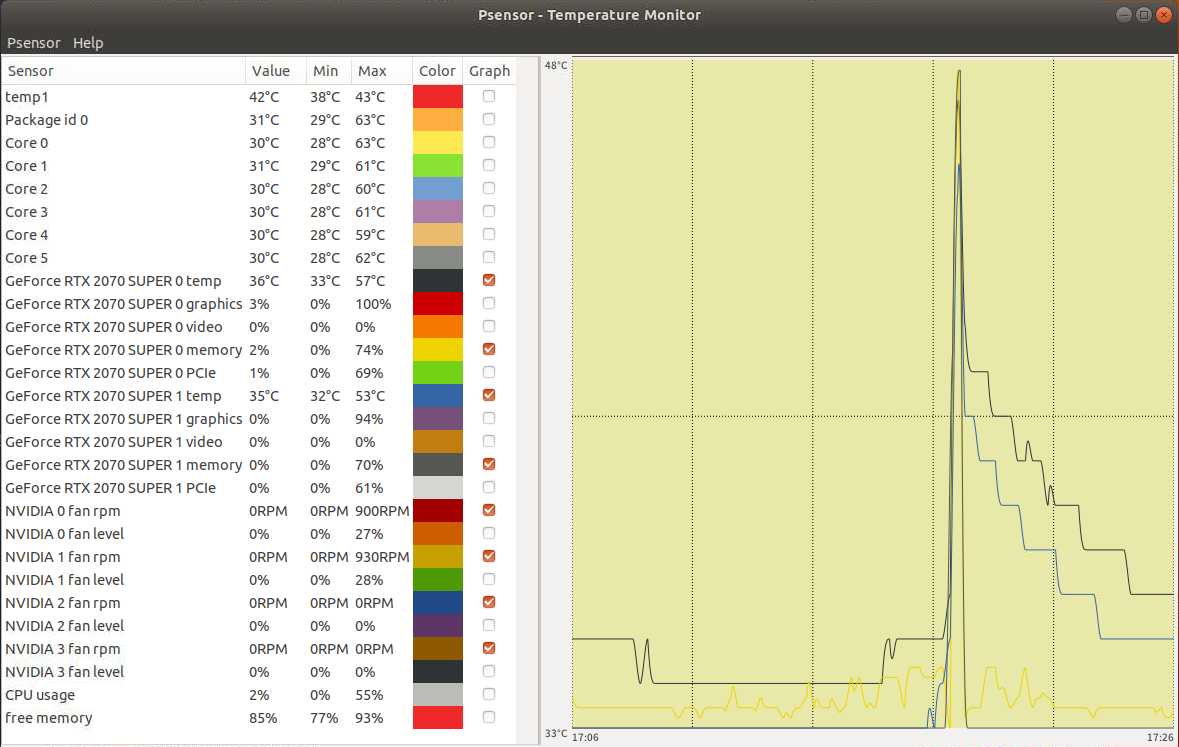
gpu が一つの場合は下記。これは出力の最後の部分だけあげます。
Step Img/sec total_loss
1 images/sec: 196.7 +/- 0.0 (jitter = 0.0) 7.765
10 images/sec: 199.5 +/- 0.7 (jitter = 1.7) 8.049
20 images/sec: 199.7 +/- 0.5 (jitter = 1.7) 7.808
30 images/sec: 199.5 +/- 0.6 (jitter = 1.3) 7.976
40 images/sec: 199.1 +/- 0.6 (jitter = 1.5) 7.591
50 images/sec: 199.3 +/- 0.5 (jitter = 1.5) 7.549
60 images/sec: 199.4 +/- 0.4 (jitter = 1.5) 7.819
70 images/sec: 198.3 +/- 0.7 (jitter = 1.9) 7.820
80 images/sec: 194.8 +/- 1.1 (jitter = 2.7) 7.847
90 images/sec: 192.0 +/- 1.2 (jitter = 4.2) 8.028
100 images/sec: 190.0 +/- 1.3 (jitter = 5.8) 8.028
----------------------------------------------------------------
total images/sec: 189.92
----------------------------------------------------------------数値は半分ぐらいになっている。このベンチマークは tensorflow 1 用だと書いてあったが、一応動いているように見える。
(20200901)
docker のインストール。virtualbox 上の ubuntu 20.04 へインストールしてみた。GPU が使えるわけではないが、とりあえず,docker に慣れることが目的。
参考:Ubuntu 20.04 LTS に docker をインストールする
コマンドを記録する。
sudo apt install docker-compose下記は root ユーザーでなくても実行できるように,自分をグループに入れるためのもの。
sudo gpasswd -a ユーザー名 docker(20200902)
docker で wordpress を起動する。
参考サイト:今更だけどDockerでWordPress環境を用意してみたら超簡単だった
イメージを持ってくる。docker pull で、mysql と WORDPRESS の2つのファイルを持ってくる。
~$ docker pull mysql:5.7.25
5.7.25: Pulling from library/mysql
Digest: sha256:dba5fed182e64064b688ccd22b2f9cad4ee88608c82f8cff21e17bab8da72b81
Status: Image is up to date for mysql:5.7.25
docker.io/library/mysql:5.7.25
~$ docker pull wordpress
Using default tag: latest
latest: Pulling from library/wordpress
bf5952930446: Pull complete
a409b57eb464: Pull complete
3192e6c84ad0: Pull complete
43553740162b: Pull complete
d8b8bba42dea: Pull complete
eb10907c0110: Pull complete
10568906f34e: Pull complete
03fe17709781: Pull complete
98171b7166c8: Pull complete
4a1bb352c362: Pull complete
cfbcb1b22459: Pull complete
9c47da96c73c: Pull complete
d5ff66b2340d: Pull complete
1a9d629afb81: Pull complete
7491b4c1cf25: Pull complete
cfd1d61e1215: Pull complete
9dc8914ad89c: Pull complete
5e36ed3f63b0: Pull complete
dfdac20bfc12: Pull complete
5221e8aad98a: Pull complete
Digest: sha256:37f77cf9a9cd50291b3550a745872603370b569d4b74eaea4e08f22753ea4179
Status: Downloaded newer image for wordpress:latest
docker.io/library/wordpress:latestコンテナの起動。
~$ docker run --name my_mysql -e MYSQL_ROOT_PASSWORD=xxxxx -d mysql:5.7.25
6a7ca88bccc13ad287a9be44cd81c6c22c49628e7c28c81ece33191845f6cd8e続けて、もうひとつのコンテナも起動。
~$ docker run -e WORDPRESS_DB_PASSWORD=xxxxx --link my_mysql:mysql -d -p 8080:80 wordpress
ee5fa915cc7a26b32f6a4847b6616be18c01d3a579d9f79739f54acc16280b9blocalhost:8080 にアクセスすると wordpress が動いている。
(20200903)
順不同であるが、コマンドを記録。
一度、ubuntu を終了して、再度 docker で wordpress を起動しようとしたら、下記のエラー。名前が重なっているというような内容。
docker: Error response from daemon: Conflict. The container name "/my_mysql" is already in use by container "1d4939229ad1edbc4b2e4ad30dc54e8a4ee2c93155c4a76d838cea739fa5a241". You have to remove (or rename) that container to be able to reuse that name.
See 'docker run --help'.そこで、現在の状況を調査する(参考サイト:Dockerイメージとコンテナの削除方法)
停止しているコンテナの確認。
docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
a22352706942 wordpress "docker-entrypoint.s…" 16 minutes ago Exited (0) 10 minutes ago busy_gates
1d4939229ad1 mysql:5.7.25 "docker-entrypoint.s…" 17 minutes ago Exited (0) 10 minutes ago my_mysql2つあるので、両方とも削除する。
~$ docker rm a22352706942
a22352706942
~$ docker rm 1d4939229ad1
1d4939229ad1このあと、前回と同じように(同じ名前で)コンテナを起動できた。
コンテナの停止。名前で指定できる。
~$ sudo docker stop tender_kare
tender_kare
~$ sudo docker stop my_mysql
my_mysqldocker イメージの削除をする。先にイメージを利用しているコンテナを削除しておく(上の方の記述を参照)。その後、イメージの確認。
~$ sudo docker images
REPOSITORY TAG IMAGE ID CREATED SIZE
wordpress latest 6158ccbb8924 28 hours ago 546MB
mysql 5.7.25 98455b9624a9 17 months ago 372MBID を指定して削除。
~$ sudo docker rmi 6158ccbb8924
Untagged: wordpress:latest
Untagged: wordpress@sha256:93ee786387237f25705610977d5f506c87ea99b1f207aa2441a027b2b5f8a7a2
Deleted: sha256:6158ccbb892411687b23ac4fd6d7c8f4e35fce2caa8118f8e3ce934cbd99b4dd
Deleted: sha256:0dd131695f295133a6f1f2b90f066d8a222768e3b72a73912c4adf04c52396b4
Deleted: sha256:109467c335d2553c688db740d686bc4cc71198a5c4f859118ca197757c9ae703
Deleted: sha256:a20b304f3c4c87a25f8c5ea1dc582e0ed3cb3b16f85ae65de322ca505109eae4
Deleted: sha256:4a0c89e004a146c22de1a97e17fe857989b51946f59dce2d83fc17496f9a14bb
Deleted: sha256:a8d2a9f9cf582707834fc9025fa48aad65ba7d4d7b4999f530b99450dec3929a
Deleted: sha256:bf9b010ae680378a86fbc021505bd69922c4942010b2f56e7dec2b59599eebb2
Deleted: sha256:6166b82101bfae46ad9b3fa68ed0b2c008ab3da54c4692daf34b40139b55563e
Deleted: sha256:8324edb0d0acf5ea5343f9a3d4bd5a6596711265d2598256c2eb1037cd633466
Deleted: sha256:a54b1508ba4eadc13394c78555693d3a89771448ee71da33de64a5928759a4e7
Deleted: sha256:df1f5315ab04605d1a13d64ff4b892be69d4d89336b85a1214b30cdd47c39b8f
Deleted: sha256:27e2fcb0c233ca7730507439deea516e1192dcc1468a878775e7acb6c82df77b
Deleted: sha256:56a340d84f17f5b4e83bd02ffd40a3b1273912dc977e450500fc224f61d43eb9
Deleted: sha256:f8899bfcfa880bd6caa5078c27b488a37f6abdce21df829ad9a7b831589bac28
Deleted: sha256:08b50110935f318104dd652795f0b0a2c6d007b368230adb8779c0a235c0b0f4
Deleted: sha256:3bcc29238c6f1ce1602b88b2317fd7429228c311b624274a54e05e8192569ead
Deleted: sha256:e7854f919e1ba15b6ac0b0e70cd2cb1eac7ca4cdcdd876c341f80b7b319ac395
Deleted: sha256:45c01c7d544fd67d36753507065e5458be16dfcf82e0e31e321c2f84e81d7d4d
Deleted: sha256:8e311722d5028e3cb61f5dea8786ed5fbc54a3e3ed4da94833a62749ebb6e7e8
Deleted: sha256:2f245d38723aa315787ea341d92c1abbcccc9cb6b0b32fde7dd02555def26970
Deleted: sha256:d0f104dc0a1f9c744b65b23b3fd4d4d3236b4656e67f776fe13f8ad8423b955cいろいろなファイルが一緒に消される。
(20200908)
docker で wordpress を動かす続き。wordpress の設定変更等を維持しておくように試みる。
参考サイト:データの永続化 docker volume 周り
上記のサイトを参考にして、まずは練習など。コマンドを記録します。事前に、コンテナ内に用意するフォルダーと対応する volume なるものを作成する。
$ docker volume create --name mysqldata
mysqldata
$ docker volume ls
DRIVER VOLUME NAME
local 3a2cbd5317d0a7515fce6a69563b431ddba4acec5a03834bae6afb4ba2fc6a4e
local 7c6b8cb4ffcba1f4786af18808c456e94d74be8bfc5e8b12518b174803efb2f4
local 30dc886e128e24e23068df50e84f408ca1d2445d7f96da184bfd4e2fe356df47
local 5833df75afe37f9a16bf2fcad7f66a454e46feec04a76195d776e6efdfbba818
local ad84ae9e906dac7e2f614088387dd8aca7e1014f7251a74017416ed924c3c803
local e3205bd67a0dcb8678186239f7b9d3a1ec891671e056b9c65b4ce4685c27e8be
local mysqldataいつの間にか色々な volume が作られていますが、mysqldata も在ります。mysqldata の詳細を見ると
$ docker volume inspect mysqldata
[
{
"CreatedAt": "2020-09-08T13:13:36+09:00",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/mysqldata/_data",
"Name": "mysqldata",
"Options": {},
"Scope": "local"
}
]とりあえず、ubuntu で試します。上記の volume をマウントした、ubuntu コンテナを起動します。コンテナでのマウント先を指定します。ちゃんとあるかどうか探してみました。
$ docker run -it -v mysqldata:/home/mysqldata ubuntu:latest /bin/bash
root@ca95c4a8e194:/# ls
bin boot dev etc home lib lib32 lib64 libx32 media mnt opt proc root run sbin srv sys tmp usr var
root@ca95c4a8e194:/# cd home/
root@ca95c4a8e194:/home# ls
mysqldataフォルダーが在りました。
続いて、wordpress の起動です。docker-compose.yml というファイルを作成。内容は下記。最初エラーが生じて上手く使用できなかった。半角スペースを挿入するかどうかが問題だった(参考サイト:YAMLError: mapping values are not allowed here)。
version: '3.3'
services:
db:
image: mysql:5.7.25
volumes: # 上の階層で指定した db_data を使いますよ
- db_data:/var/lib/mysql
restart: always
environment:
MYSQL_ROOT_PASSWORD: rootpw
MYSQL_DATABASE: wordpress
MYSQL_USER: wordpress
MYSQL_PASSWORD: wordpresspw
wordpress:
depends_on:
- db
image: wordpress:latest
ports:
- "8080:80"
restart: always
volumes:
- ./htmldata/:/var/www/html/
environment:
WORDPRESS_DB_HOST: db:3306
WORDPRESS_DB_USER: wordpress
WORDPRESS_DB_PASSWORD: wordpresspw
volumes:
db_data: # まずこの名前で volume を作るdocker の volume は事前に準備しなかった。下記のコマンドでコンテナを起動。
docker-compose upこの返事は相当長いものだった。
$ docker-compose up
Creating network "docker_default" with the default driver
Creating docker_db_1 ... done
Creating docker_wordpress_1 ... done
Attaching to docker_db_1, docker_wordpress_1
db_1 | 2020-09-08T07:18:14.490866Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use --explicit_defaults_for_timestamp server option (see documentation for more details).
db_1 | 2020-09-08T07:18:14.491939Z 0 [Note] mysqld (mysqld 5.7.25) starting as process 1 ...
db_1 | 2020-09-08T07:18:14.495653Z 0 [Note] InnoDB: PUNCH HOLE support available
db_1 | 2020-09-08T07:18:14.495692Z 0 [Note] InnoDB: Mutexes and rw_locks use GCC atomic builtins
db_1 | 2020-09-08T07:18:14.495704Z 0 [Note] InnoDB: Uses event mutexes
db_1 | 2020-09-08T07:18:14.495715Z 0 [Note] InnoDB: GCC builtin __atomic_thread_fence() is used for memory barrier
db_1 | 2020-09-08T07:18:14.495725Z 0 [Note] InnoDB: Compressed tables use zlib 1.2.11
db_1 | 2020-09-08T07:18:14.495735Z 0 [Note] InnoDB: Using Linux native AIO
db_1 | 2020-09-08T07:18:14.496020Z 0 [Note] InnoDB: Number of pools: 1
db_1 | 2020-09-08T07:18:14.496161Z 0 [Note] InnoDB: Using CPU crc32 instructions
db_1 | 2020-09-08T07:18:14.498570Z 0 [Note] InnoDB: Initializing buffer pool, total size = 128M, instances = 1, chunk size = 128M
db_1 | 2020-09-08T07:18:14.508490Z 0 [Note] InnoDB: Completed initialization of buffer pool
db_1 | 2020-09-08T07:18:14.510028Z 0 [Note] InnoDB: If the mysqld execution user is authorized, page cleaner thread priority can be changed. See the man page of setpriority().
db_1 | 2020-09-08T07:18:14.529597Z 0 [Note] InnoDB: Highest supported file format is Barracuda.
db_1 | 2020-09-08T07:18:14.622849Z 0 [Note] InnoDB: Creating shared tablespace for temporary tables
db_1 | 2020-09-08T07:18:14.622896Z 0 [Note] InnoDB: Setting file './ibtmp1' size to 12 MB. Physically writing the file full; Please wait ...
db_1 | 2020-09-08T07:18:14.835131Z 0 [Note] InnoDB: File './ibtmp1' size is now 12 MB.
db_1 | 2020-09-08T07:18:14.836191Z 0 [Note] InnoDB: 96 redo rollback segment(s) found. 96 redo rollback segment(s) are active.
db_1 | 2020-09-08T07:18:14.836216Z 0 [Note] InnoDB: 32 non-redo rollback segment(s) are active.
db_1 | 2020-09-08T07:18:14.836617Z 0 [Note] InnoDB: 5.7.25 started; log sequence number 13734298
db_1 | 2020-09-08T07:18:14.836749Z 0 [Note] InnoDB: Loading buffer pool(s) from /var/lib/mysql/ib_buffer_pool
db_1 | 2020-09-08T07:18:14.836838Z 0 [Note] Plugin 'FEDERATED' is disabled.
db_1 | 2020-09-08T07:18:14.841254Z 0 [Note] Found ca.pem, server-cert.pem and server-key.pem in data directory. Trying to enable SSL support using them.
db_1 | 2020-09-08T07:18:14.841525Z 0 [Warning] CA certificate ca.pem is self signed.
db_1 | 2020-09-08T07:18:14.842984Z 0 [Note] Server hostname (bind-address): '*'; port: 3306
db_1 | 2020-09-08T07:18:14.843226Z 0 [Note] IPv6 is available.
db_1 | 2020-09-08T07:18:14.843239Z 0 [Note] - '::' resolves to '::';
db_1 | 2020-09-08T07:18:14.843256Z 0 [Note] Server socket created on IP: '::'.
db_1 | 2020-09-08T07:18:14.844321Z 0 [Note] InnoDB: Buffer pool(s) load completed at 200908 7:18:14
db_1 | 2020-09-08T07:18:14.847380Z 0 [Warning] Insecure configuration for --pid-file: Location '/var/run/mysqld' in the path is accessible to all OS users. Consider choosing a different directory.
db_1 | 2020-09-08T07:18:14.848291Z 0 [Warning] 'user' entry 'root@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.848315Z 0 [Warning] 'user' entry 'mysql.session@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.848323Z 0 [Warning] 'user' entry 'mysql.sys@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.848371Z 0 [Warning] 'db' entry 'performance_schema mysql.session@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.848377Z 0 [Warning] 'db' entry 'sys mysql.sys@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.848388Z 0 [Warning] 'proxies_priv' entry '@ root@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.861849Z 0 [Warning] 'tables_priv' entry 'user mysql.session@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.861869Z 0 [Warning] 'tables_priv' entry 'sys_config mysql.sys@localhost' ignored in --skip-name-resolve mode.
db_1 | 2020-09-08T07:18:14.890137Z 0 [Note] Event Scheduler: Loaded 0 events
db_1 | 2020-09-08T07:18:14.901595Z 0 [Note] mysqld: ready for connections.
db_1 | Version: '5.7.25' socket: '/var/run/mysqld/mysqld.sock' port: 3306 MySQL Community Server (GPL)
wordpress_1 | AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 172.19.0.3. Set the 'ServerName' directive globally to suppress this message
wordpress_1 | AH00558: apache2: Could not reliably determine the server's fully qualified domain name, using 172.19.0.3. Set the 'ServerName' directive globally to suppress this message
wordpress_1 | [Tue Sep 08 07:18:15.507048 2020] [mpm_prefork:notice] [pid 1] AH00163: Apache/2.4.38 (Debian) PHP/7.4.9 configured -- resuming normal operations
wordpress_1 | [Tue Sep 08 07:18:15.507097 2020] [core:notice] [pid 1] AH00094: Command line: 'apache2 -D FOREGROUND'サイトにアクセスすると上記のログに追加される。ログが標準画面に表示されるようだ。localhost:8080 なら動いている。The Box というテーマを利用してみた。
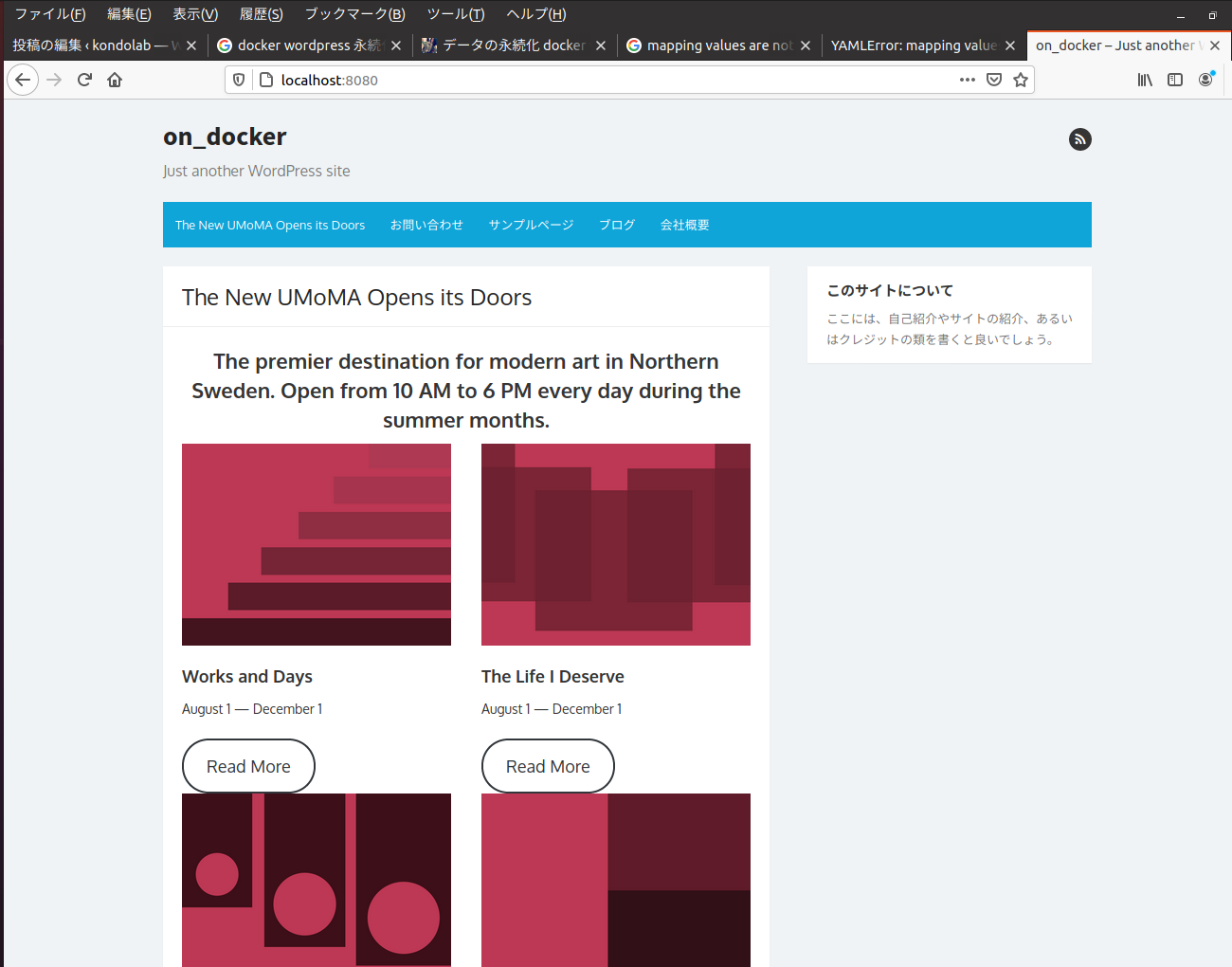
いったん終了する。ctrl+c で止めてから、下記のコマンド。
$ docker-compose down
Removing docker_wordpress_1 ... done
Removing docker_db_1 ... done
Removing network docker_defaultもう一回、起動してみる。結果、The Box テーマを適用された状態で表示された。全く同じ画面なのでキャプチャーは省略します。一応永続化はできたようだ。
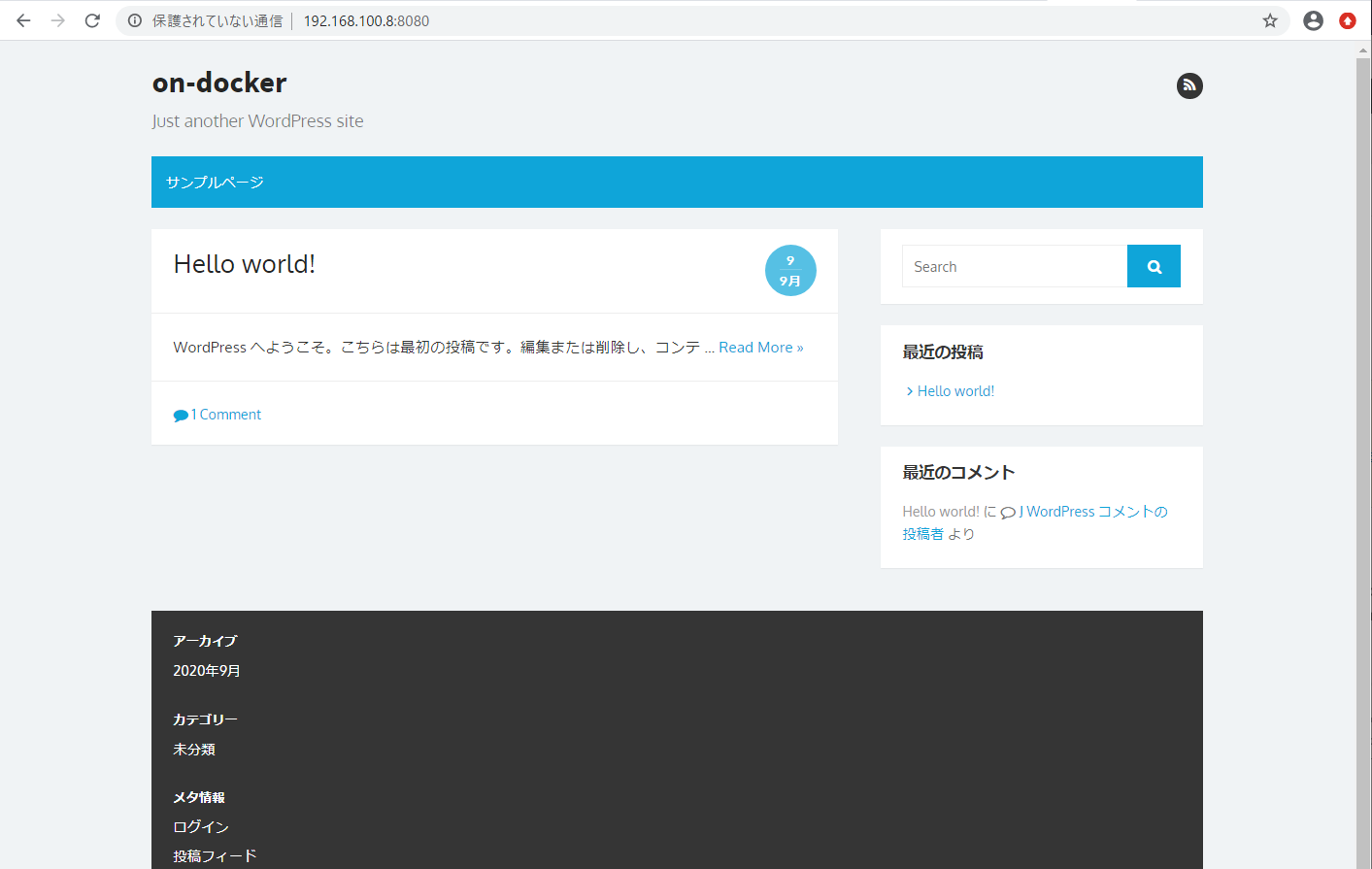
localhost 以外からだと,表示がおかしい。css が読み込まれていないような表示になった。

上記の症状は wordpress のインストール時,サーバーのアドレスがコンフィグファイルに書き込まれる際に,localhost と記入されている故ではないかと考えて,一旦,mysql 用の volume を削除してデーターベースを初期化し,再びコンテナを起動して,wordpress の再設定を試みた。今回は localhost ではなく,外部から IP アドレスでアクセスする。インストールを終えると,外部からのアクセスに対して、下図のようにそれらしい表示となった。
(20200909)
docker で GPU を利用すべく、もとの RTX2070super x 2 枚刺しのパソコンに戻る。環境を確認します。
$ nvidia-smi
Fri Sep 11 14:26:39 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 207... On | 00000000:01:00.0 On | N/A |
| 0% 33C P8 12W / 215W | 152MiB / 7979MiB | 1% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 207... On | 00000000:02:00.0 Off | N/A |
| 0% 32C P8 7W / 215W | 1MiB / 7982MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1092 G /usr/lib/xorg/Xorg 82MiB |
| 0 N/A N/A 1228 G /usr/bin/gnome-shell 68MiB |
+-----------------------------------------------------------------------------+まずは docker のインストールから。下記のサイトに従って作業。
参考サイト:NVIDIA Docker って今どうなってるの? (20.09 版)
$ curl https://get.docker.com | sh
% Total % Received % Xferd Average Speed Time Time Time Current
Dload Upload Total Spent Left Speed
100 13857 100 13857 0 0 80563 0 --:--:-- --:--:-- --:--:-- 80563
# Executing docker install script, commit: 26ff363bcf3b3f5a00498ac43694bf1c7d9ce16c
+ sudo -E sh -c apt-get update -qq >/dev/null
+ sudo -E sh -c DEBIAN_FRONTEND=noninteractive apt-get install -y -qq apt-transport-https ca-certificates curl >/dev/null
+ sudo -E sh -c curl -fsSL "https://download.docker.com/linux/ubuntu/gpg" | apt-key add -qq - >/dev/null
Warning: apt-key output should not be parsed (stdout is not a terminal)
+ sudo -E sh -c echo "deb [arch=amd64] https://download.docker.com/linux/ubuntu bionic stable" > /etc/apt/sources.list.d/docker.list
+ sudo -E sh -c apt-get update -qq >/dev/null
+ [ -n ]
+ sudo -E sh -c apt-get install -y -qq --no-install-recommends docker-ce >/dev/null
+ sudo -E sh -c docker version
Client: Docker Engine - Community
Version: 19.03.12
API version: 1.40
Go version: go1.13.10
Git commit: 48a66213fe
Built: Mon Jun 22 15:45:36 2020
OS/Arch: linux/amd64
Experimental: false
Server: Docker Engine - Community
Engine:
Version: 19.03.12
API version: 1.40 (minimum version 1.12)
Go version: go1.13.10
Git commit: 48a66213fe
Built: Mon Jun 22 15:44:07 2020
OS/Arch: linux/amd64
Experimental: false
containerd:
Version: 1.2.13
GitCommit: 7ad184331fa3e55e52b890ea95e65ba581ae3429
runc:
Version: 1.0.0-rc10
GitCommit: dc9208a3303feef5b3839f4323d9beb36df0a9dd
docker-init:
Version: 0.18.0
GitCommit: fec3683
If you would like to use Docker as a non-root user, you should now consider
adding your user to the "docker" group with something like:
sudo usermod -aG docker friend
Remember that you will have to log out and back in for this to take effect!
WARNING: Adding a user to the "docker" group will grant the ability to run
containers which can be used to obtain root privileges on the
docker host.
Refer to https://docs.docker.com/engine/security/security/#docker-daemon-attack-surface
for more information.続けて下記のコマンド。
$ sudo systemctl start docker && sudo systemctl enable docker
Synchronizing state of docker.service with SysV service script with /lib/systemd/systemd-sysv-install.
Executing: /lib/systemd/systemd-sysv-install enable docker通常のユーザーで docker を利用できるように、グループに自分を追加する。
$ sudo usermod -aG docker 自分あとはここを参照しながら下記のコマンドを打った。
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
sudo apt-get update
sudo apt-get install -y nvidia-docker2
sudo systemctl restart dockerテスト用のコンテナを動かす。
$ sudo docker run --rm --gpus all nvidia/cuda:11.0-base nvidia-smi
Unable to find image 'nvidia/cuda:11.0-base' locally
11.0-base: Pulling from nvidia/cuda
54ee1f796a1e: Pull complete
f7bfea53ad12: Pull complete
46d371e02073: Pull complete
b66c17bbf772: Pull complete
3642f1a6dfb3: Pull complete
e5ce55b8b4b9: Pull complete
155bc0332b0a: Pull complete
Digest: sha256:774ca3d612de15213102c2dbbba55df44dc5cf9870ca2be6c6e9c627fa63d67a
Status: Downloaded newer image for nvidia/cuda:11.0-base
Wed Sep 9 09:15:49 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.51.06 Driver Version: 450.51.06 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce RTX 207... On | 00000000:01:00.0 On | N/A |
| 0% 34C P8 13W / 215W | 174MiB / 7979MiB | 10% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 207... On | 00000000:02:00.0 Off | N/A |
| 0% 33C P8 7W / 215W | 1MiB / 7982MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
+-----------------------------------------------------------------------------+上手くいった?
このサイトを参考にして、とりあえず何かコンテナを動かしてみる。コマンドは下記で、jyupyter が利用できるもの。
docker pull tensorflow/tensorflow:latest-py3
docker run -it -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyter実行したときのレスポンス。sudo で実行した。
$ sudo docker run -it -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyter
Unable to find image 'tensorflow/tensorflow:latest-py3-jupyter' locally
latest-py3-jupyter: Pulling from tensorflow/tensorflow
2746a4a261c9: Already exists
4c1d20cdee96: Already exists
0d3160e1d0de: Already exists
c8e37668deea: Already exists
e52cad4ccd83: Already exists
e97116da5f98: Already exists
75c61371a2e3: Already exists
8592f093fc78: Already exists
dccb0709d7fb: Already exists
107f0b841886: Already exists
edc69fe5c6be: Already exists
3d7f9e997aed: Pull complete
1575375ec2e9: Pull complete
a574cd2a2ef5: Pull complete
a1565ebf3379: Pull complete
af0d84cd6cdc: Pull complete
8c1a10281be2: Pull complete
649bf527b9db: Pull complete
62895ac313e8: Pull complete
0d2cfdddc1a6: Pull complete
a315501e4ca9: Pull complete
146e7ce36cb8: Pull complete
e638992c0d5d: Pull complete
ea6d34ce743b: Pull complete
3bf310c11c24: Pull complete
e4e0bb9d2283: Pull complete
Digest: sha256:37709ed9fcb2e57132710d521b5a6f826bc022e9f137750cc19728a1533f08e1
Status: Downloaded newer image for tensorflow/tensorflow:latest-py3-jupyter
________ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
WARNING: You are running this container as root, which can cause new files in
mounted volumes to be created as the root user on your host machine.
To avoid this, run the container by specifying your user's userid:
$ docker run -u $(id -u):$(id -g) args...
[I 16:03:10.363 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
jupyter_http_over_ws extension initialized. Listening on /http_over_websocket
[I 16:03:10.503 NotebookApp] Serving notebooks from local directory: /tf
[I 16:03:10.503 NotebookApp] The Jupyter Notebook is running at:
[I 16:03:10.503 NotebookApp] http://5e4fea31b956:8888/?token=d7f9b426c52afcd12333f0aab8b132f30397a00d50a12240
[I 16:03:10.503 NotebookApp] or http://127.0.0.1:8888/?token=d7f9b426c52afcd12333f0aab8b132f30397a00d50a12240
[I 16:03:10.503 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 16:03:10.506 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-1-open.html
Or copy and paste one of these URLs:
http://5e4fea31b956:8888/?token=d7f9b426c52afcd12333f0aab8b132f30397a00d50a12240
or http://127.0.0.1:8888/?token=d7f9b426c52afcd12333f0aab8b132f30397a00d50a12240
[I 16:03:58.024 NotebookApp] 302 GET / (172.17.0.1) 0.42ms
[I 16:03:58.026 NotebookApp] 302 GET /tree? (172.17.0.1) 0.48ms
[W 16:04:51.383 NotebookApp] 401 POST /login?next=%2Ftree%3F (172.17.0.1) 0.94ms referer=http://localhost:8888/login?next=%2Ftree%3F
[W 16:07:36.535 NotebookApp] 401 POST /login?next=%2Ftree%3F (172.17.0.1) 1.05ms referer=http://localhost:8888/login?next=%2Ftree%3F
[W 16:07:55.703 NotebookApp] 401 POST /login?next=%2Ftree%3F (172.17.0.1) 0.89ms referer=http://localhost:8888/login?next=%2Ftree%3F
[W 16:08:25.930 NotebookApp] 401 POST /login?next=%2Ftree%3F (172.17.0.1) 0.94ms referer=http://localhost:8888/login?next=%2Ftree%3F
[W 16:08:43.800 NotebookApp] 401 POST /login?next=%2Ftree%3F (172.17.0.1) 0.90ms referer=http://localhost:8888/login?next=%2Ftree%3F
[W 16:09:21.194 NotebookApp] 401 POST /login?next=%2Ftree%3F (172.17.0.1) 0.92ms referer=http://localhost:8888/login?next=%2Ftree%3F
[I 16:09:56.678 NotebookApp] 302 GET /?token=c8de56fa...%20::%20/Users/you/notebooks (172.17.0.1) 0.37ms
[I 16:09:56.680 NotebookApp] 302 GET /tree?token=c8de56fa...%20::%20/Users/you/notebooks (172.17.0.1) 0.52ms
[I 16:11:23.088 NotebookApp] 302 GET /?token=d7f9b426c52afcd12333f0aab8b132f30397a00d50a12240 (172.17.0.1) 0.39ms
[I 16:11:38.011 NotebookApp] Creating new notebook in
[I 16:11:38.019 NotebookApp] Writing notebook-signing key to /root/.local/share/jupyter/notebook_secret
[I 16:11:38.539 NotebookApp] Kernel started: c0ee8cda-44be-4035-87d9-cad7cbc9c76a
[I 16:13:38.534 NotebookApp] Saving file at /Untitled.ipynb
[I 02:03:39.300 NotebookApp] Saving file at /Untitled.ipynb出力の中にあるリンク http://127.0.0.1:8888/?token=d7f9b426c52afcd12333f0aab8b132f30397a00d50a12240 をブラウザで開くと、jupyter notebook が表示された。
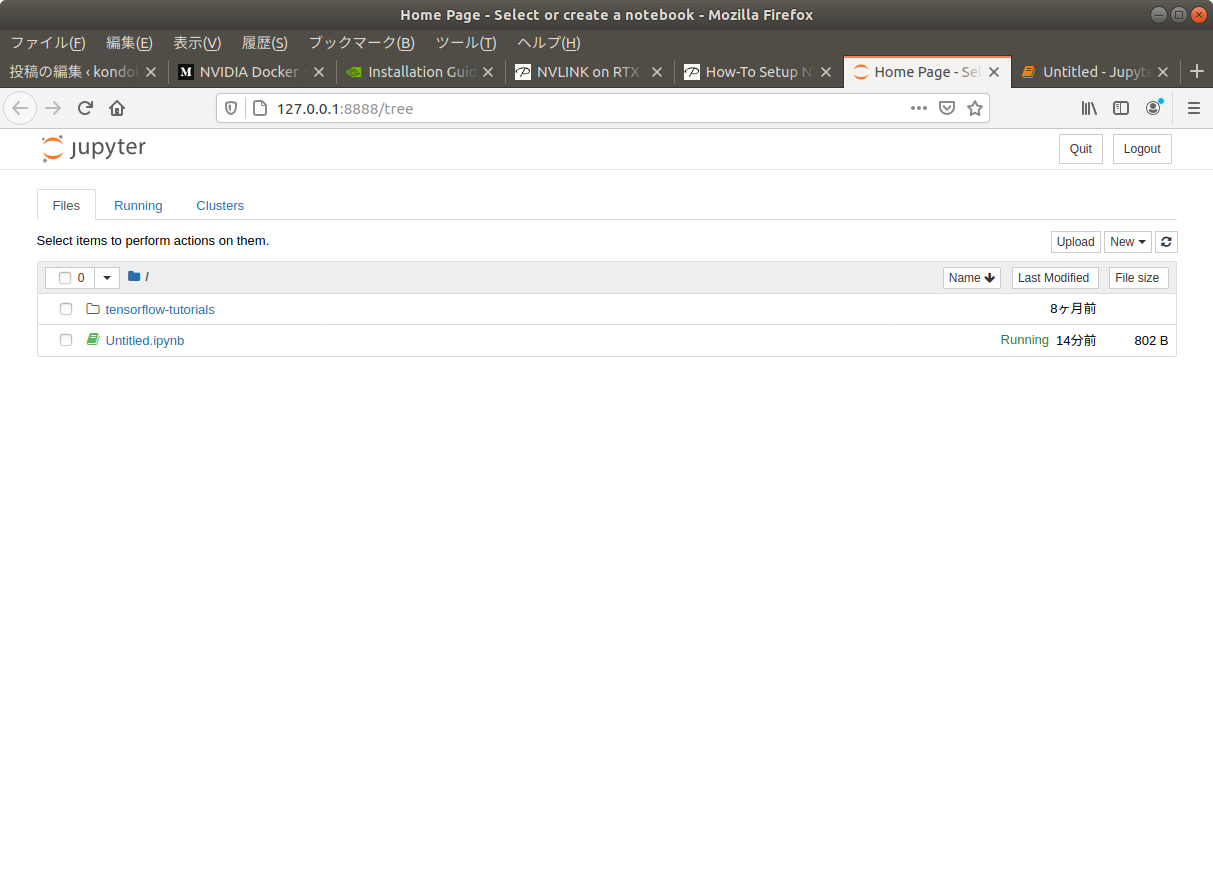
この先は、本に載っているコードが実行できるようなコンテナを用意することが目標かな? tensorflow の version 1 のコードが動く環境があれば、本のコードが試せると思う。
(20200911)
一旦、ubuntu18 を入れ直す。このページによると、ホストにはビデオカードのドライバーだけを入れておけば良いということなので、それに合わせて入れ直してみる。ビデオカードのドライバーは下図の追加のドライバーから入れてみた。
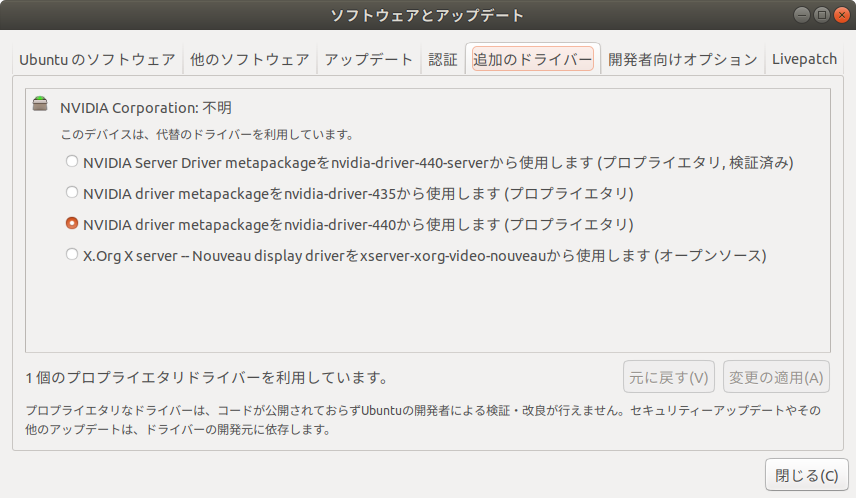
このあとは以前のコマンドの繰り返しとなるが、まとめておきます(参考サイト)。
$ sudo apt install curl
$ curl https://get.docker.com | sh
$ sudo systemctl start docker && sudo systemctl enable docker
$ sudo usermod -aG docker ユーザー名
$ distribution=$(. /etc/os-release;echo $ID$VERSION_ID)
$ curl -s -L https://nvidia.github.io/nvidia-docker/gpgkey | sudo apt-key add -
$ curl -s -L https://nvidia.github.io/nvidia-docker/$distribution/nvidia-docker.list | sudo tee /etc/apt/sources.list.d/nvidia-docker.list
$ sudo apt-get update
$ sudo apt-get install -y nvidia-docker2
$ sudo systemctl restart docker確認をしてみる。CUDA を入れた憶えはないのだけど。
$ nvidia-smi
Fri Sep 11 18:27:22 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 440.100 Driver Version: 440.100 CUDA Version: 10.2 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce RTX 207... Off | 00000000:01:00.0 On | N/A |
| 0% 34C P8 13W / 215W | 189MiB / 7974MiB | 2% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce RTX 207... Off | 00000000:02:00.0 Off | N/A |
| 0% 33C P8 7W / 215W | 1MiB / 7982MiB | 0% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 900 G /usr/lib/xorg/Xorg 113MiB |
| 0 1083 G /usr/bin/gnome-shell 70MiB |
| 0 1903 G /usr/lib/firefox/firefox 2MiB |
+-----------------------------------------------------------------------------+
docker のバージョンを確認。
$ docker -v
Docker version 19.03.12, build 48a66213feCUDA のバージョンを確認するコマンドとして nvcc -V があるが、このコマンドはインストールされていないようである。つまり CUDA はインストールされていないということだろうか。
これも繰り返しになるがこのサイトを参考にして、jyupyter が利用できるコンテナを動かしてみる。コマンドは下記。
docker pull tensorflow/tensorflow:latest-py3
docker run -it -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyterコマンドの出力をあげます。
$ docker pull tensorflow/tensorflow:latest-py3
latest-py3: Pulling from tensorflow/tensorflow
2746a4a261c9: Pull complete
4c1d20cdee96: Pull complete
0d3160e1d0de: Pull complete
c8e37668deea: Pull complete
e52cad4ccd83: Pull complete
e97116da5f98: Pull complete
75c61371a2e3: Pull complete
8592f093fc78: Pull complete
dccb0709d7fb: Pull complete
107f0b841886: Pull complete
edc69fe5c6be: Pull complete
Digest: sha256:14ec674cefd622aa9d45f07485500da254acaf8adfef80bd0f279db03c735689
Status: Downloaded newer image for tensorflow/tensorflow:latest-py3
docker.io/tensorflow/tensorflow:latest-py3
$ docker run -it -p 8888:8888 tensorflow/tensorflow:latest-py3-jupyter
Unable to find image 'tensorflow/tensorflow:latest-py3-jupyter' locally
latest-py3-jupyter: Pulling from tensorflow/tensorflow
2746a4a261c9: Already exists
4c1d20cdee96: Already exists
0d3160e1d0de: Already exists
c8e37668deea: Already exists
e52cad4ccd83: Already exists
e97116da5f98: Already exists
75c61371a2e3: Already exists
8592f093fc78: Already exists
dccb0709d7fb: Already exists
107f0b841886: Already exists
edc69fe5c6be: Already exists
3d7f9e997aed: Pull complete
1575375ec2e9: Pull complete
a574cd2a2ef5: Pull complete
a1565ebf3379: Pull complete
af0d84cd6cdc: Pull complete
8c1a10281be2: Pull complete
649bf527b9db: Pull complete
62895ac313e8: Pull complete
0d2cfdddc1a6: Pull complete
a315501e4ca9: Pull complete
146e7ce36cb8: Pull complete
e638992c0d5d: Pull complete
ea6d34ce743b: Pull complete
3bf310c11c24: Pull complete
e4e0bb9d2283: Pull complete
Digest: sha256:37709ed9fcb2e57132710d521b5a6f826bc022e9f137750cc19728a1533f08e1
Status: Downloaded newer image for tensorflow/tensorflow:latest-py3-jupyter
________ _______________
___ __/__________________________________ ____/__ /________ __
__ / _ _ \_ __ \_ ___/ __ \_ ___/_ /_ __ /_ __ \_ | /| / /
_ / / __/ / / /(__ )/ /_/ / / _ __/ _ / / /_/ /_ |/ |/ /
/_/ \___//_/ /_//____/ \____//_/ /_/ /_/ \____/____/|__/
WARNING: You are running this container as root, which can cause new files in
mounted volumes to be created as the root user on your host machine.
To avoid this, run the container by specifying your user's userid:
$ docker run -u $(id -u):$(id -g) args...
[I 17:01:04.729 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
jupyter_http_over_ws extension initialized. Listening on /http_over_websocket
[I 17:01:04.869 NotebookApp] Serving notebooks from local directory: /tf
[I 17:01:04.869 NotebookApp] The Jupyter Notebook is running at:
[I 17:01:04.869 NotebookApp] http://4dbeafa44de8:8888/?token=fbddcfe328f0511dff608cbcb182a58827ca9573930cb069
[I 17:01:04.869 NotebookApp] or http://127.0.0.1:8888/?token=fbddcfe328f0511dff608cbcb182a58827ca9573930cb069
[I 17:01:04.869 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[C 17:01:04.872 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-1-open.html
Or copy and paste one of these URLs:
http://4dbeafa44de8:8888/?token=fbddcfe328f0511dff608cbcb182a58827ca9573930cb069
or http://127.0.0.1:8888/?token=fbddcfe328f0511dff608cbcb182a58827ca9573930cb069
[I 17:02:15.433 NotebookApp] 302 GET /?token=fbddcfe328f0511dff608cbcb182a58827ca9573930cb069 (172.17.0.1) 0.48ms
上記の出力の最後の方にある URL http://127.0.0.1:8888/?token=fbddcfe328f0511dff608cbcb182a58827ca9573930cb069 をブラウザで開くと、jupyter が動いていた。
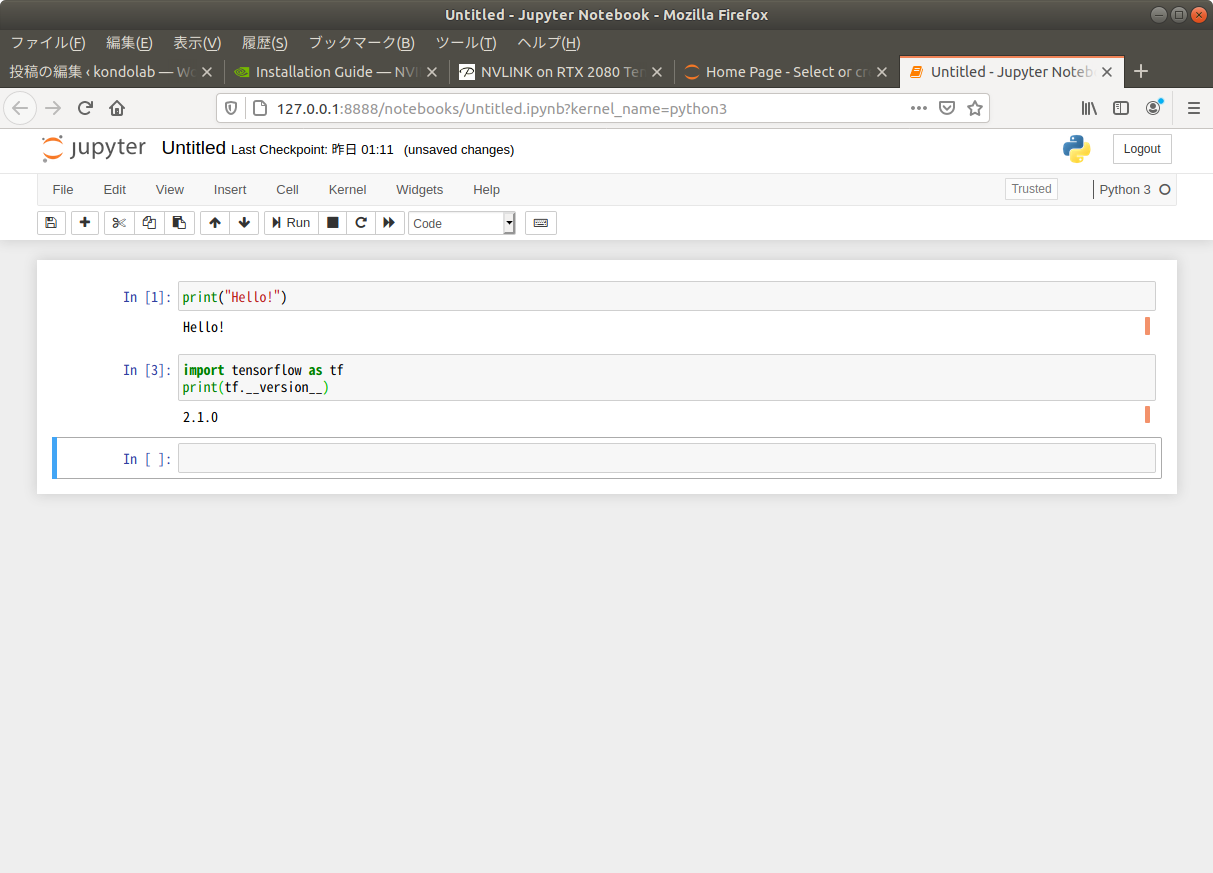
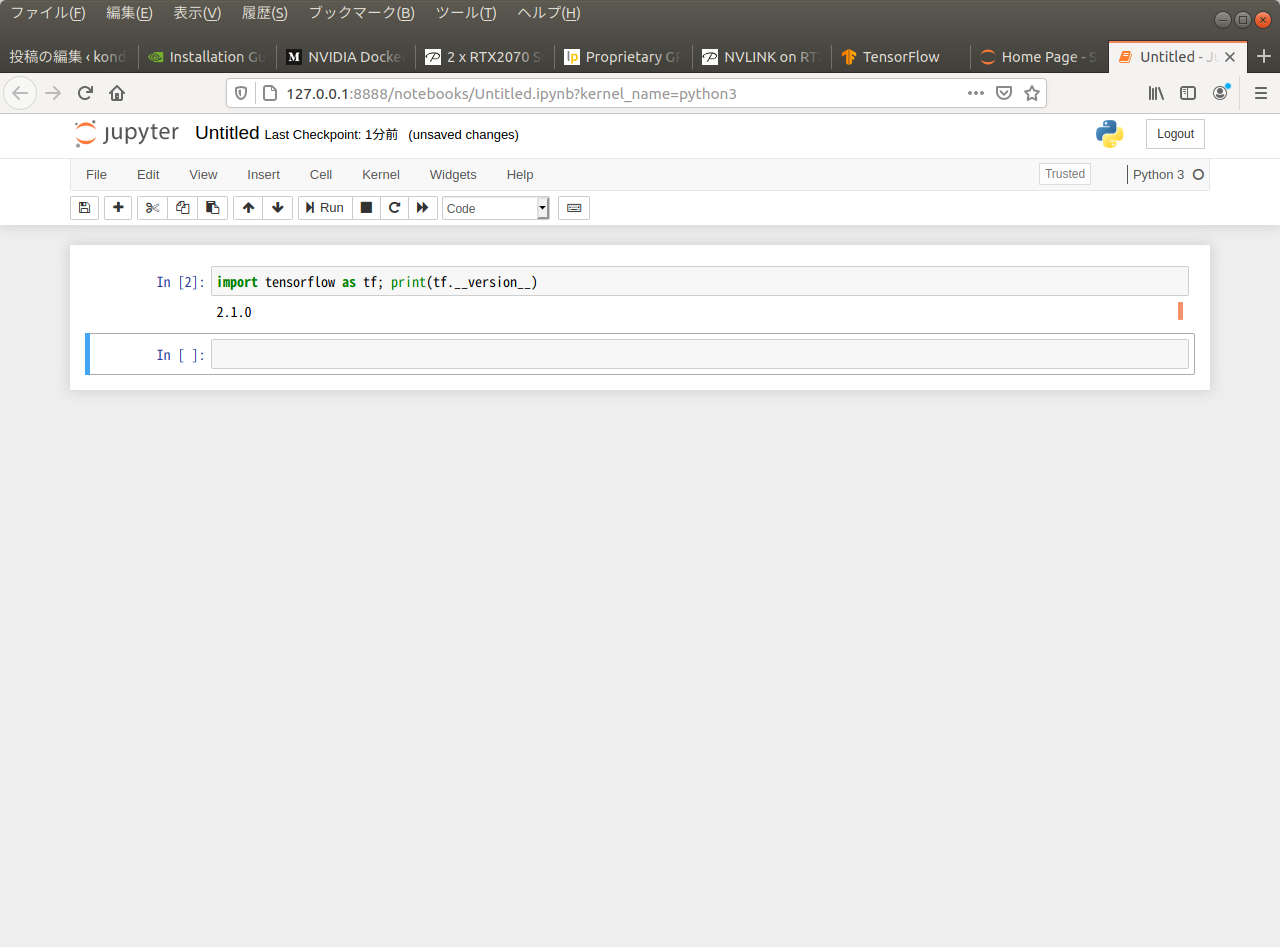
tensorflow のバージョンを確認する。bash で打つなら下記。tensorflow2 用のもの。
python3 -c 'import tensorflow as tf; print(tf.__version__)'jyupyter 上で実行してみた。
Ubuntu 18.04 でCUDA, Cudnn, Tensorflow GPU のインストールにあるのを参考にして GPU を認識できているかどうか調べてみた。
コマンドは下記。
from tensorflow.python.client import device_lib
device_lib.list_local_devices()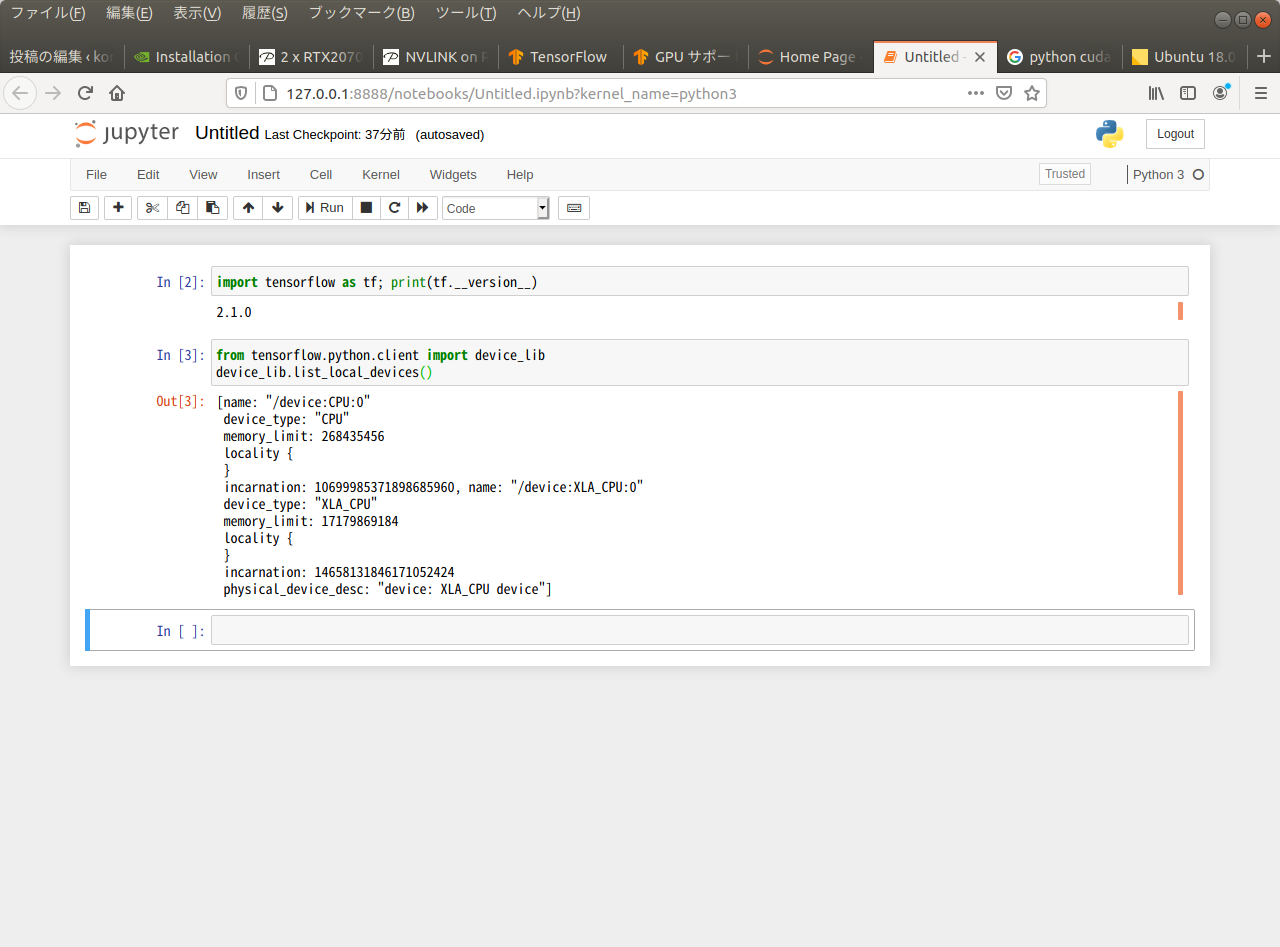
GPU の文字が見当たらない。コンテナがいけなかったか?
他のイメージを pull してみる(参考サイト)。
docker pull tensorflow/tensorflow:latest-gpu-jupyterコンテナの起動は下記の様にした。--gpus all を付けてみた。
$ docker run -it -p 8888:8888 --gpus all tensorflow/tensorflow:latest-gpu-jupyter全部の出力は長すぎて入っていないが、GPU の文字が現れた。
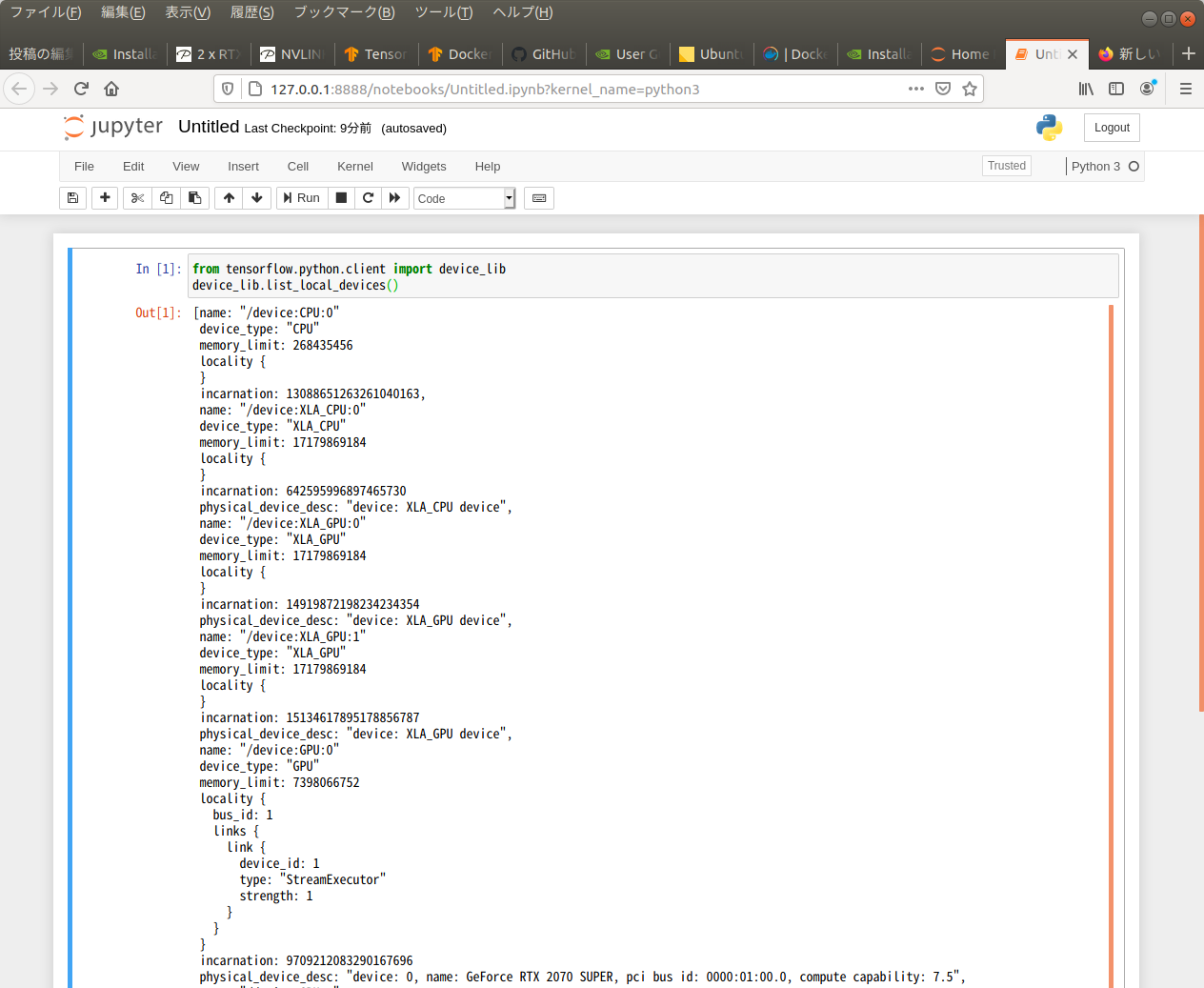
出力をテキストで拾ってみました。
[name: "/device:CPU:0"
device_type: "CPU"
memory_limit: 268435456
locality {
}
incarnation: 13088651263261040163,
name: "/device:XLA_CPU:0"
device_type: "XLA_CPU"
memory_limit: 17179869184
locality {
}
incarnation: 642595996897465730
physical_device_desc: "device: XLA_CPU device",
name: "/device:XLA_GPU:0"
device_type: "XLA_GPU"
memory_limit: 17179869184
locality {
}
incarnation: 14919872198234234354
physical_device_desc: "device: XLA_GPU device",
name: "/device:XLA_GPU:1"
device_type: "XLA_GPU"
memory_limit: 17179869184
locality {
}
incarnation: 15134617895178856787
physical_device_desc: "device: XLA_GPU device",
name: "/device:GPU:0"
device_type: "GPU"
memory_limit: 7398066752
locality {
bus_id: 1
links {
link {
device_id: 1
type: "StreamExecutor"
strength: 1
}
}
}
incarnation: 9709212083290167696
physical_device_desc: "device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5",
name: "/device:GPU:1"
device_type: "GPU"
memory_limit: 7614296224
locality {
bus_id: 1
links {
link {
type: "StreamExecutor"
strength: 1
}
}
}
incarnation: 13142821548236644970
physical_device_desc: "device: 1, name: GeForce RTX 2070 SUPER, pci bus id: 0000:02:00.0, compute capability: 7.5"]あとは、古い tensorflow が動くようにしたい。
(20200913)
他の古いイメージをこのサイトから選んで pull してみる。
$ docker pull tensorflow/tensorflow:1.14.0-gpu-py3-jupyterコンテナを起動する。
$ docker run -it -p 8888:8888 --gpus all tensorflow/tensorflow:1.14.0-gpu-py3-jupyterjyupyter を開いてみる。tensorflow のバージョンと GPU を認識しているかどうかを試す。
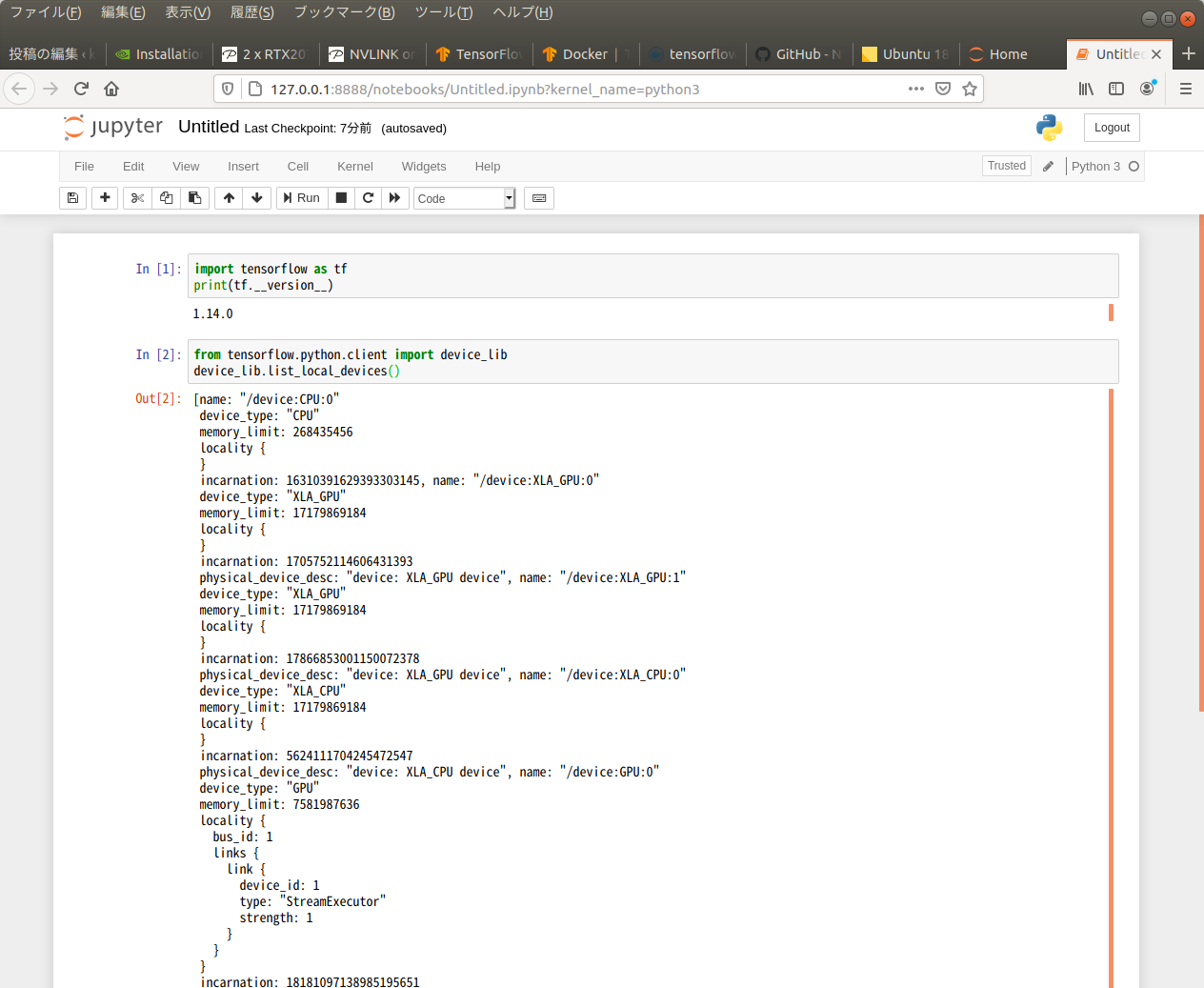
大丈夫なようだ。『scikit-learnとtensorflowによる実践機械学習』のコードを試してみた。
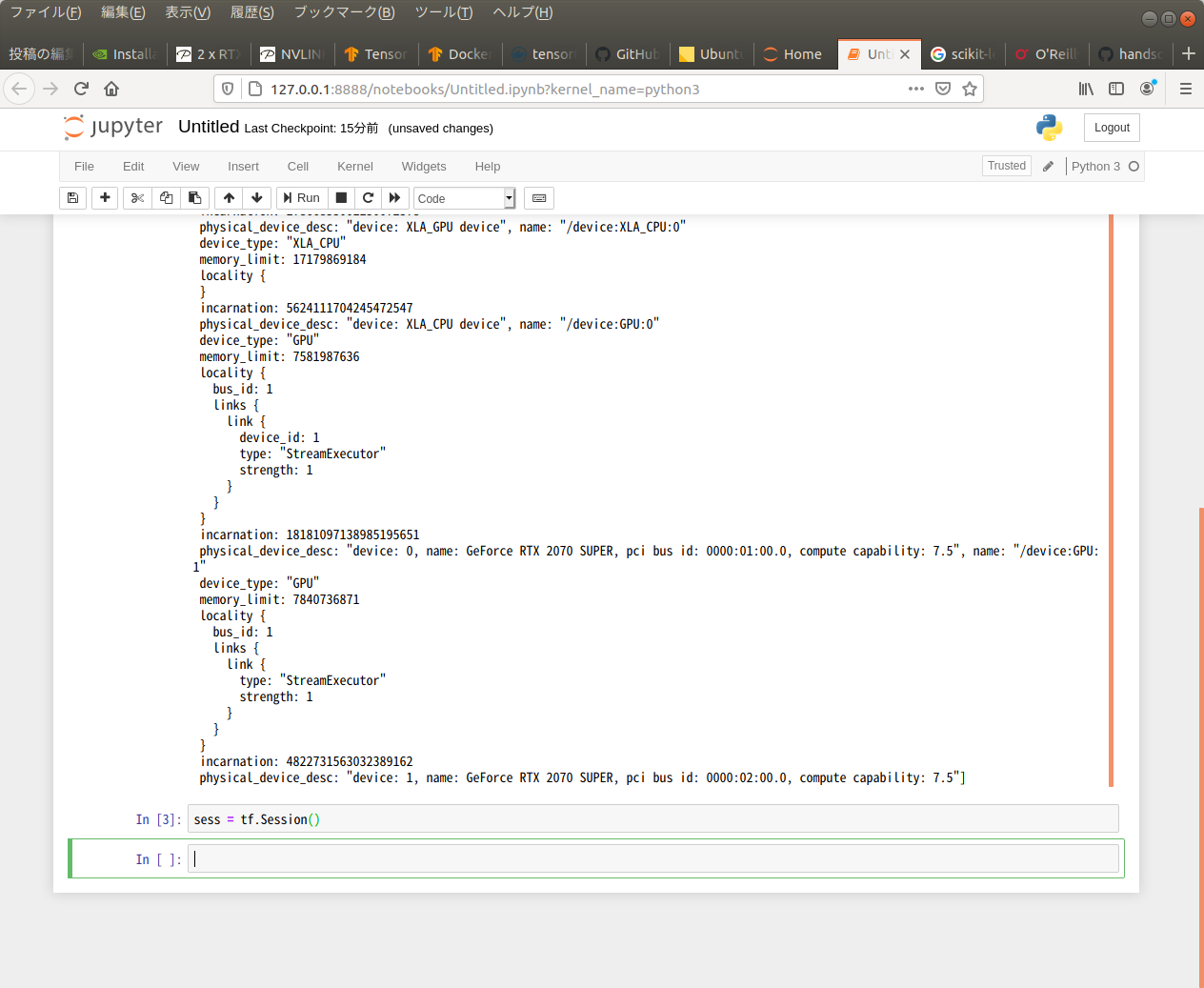
Session が利用できる。これで、この本が読めるのではないかな?
(20200914)
ここにあるようなベンチマークを動かしてみたい。まずはイメージの取得。
$ docker run --runtime=nvidia --rm -it -v $HOME/projects:/projects nvcr.io/nvidia/tensorflow:19.02-py3上記では自分のホームディレクトリーに projects というフォルダーを作っておけば、起動したコンテナの /projects フォルダーとつながるようになっている。bash が起動されて、どの python コードを実行するのかよく分からなかったが、ここにある内容をやってみた。コマンドは下記。
mpiexec --allow-run-as-root --bind-to socket -np 2 python /opt/tensorflow/nvidia-examples/cnn/resnet.py --layers=50 --precision=fp16 --batch_size=128かなりの量の応答メッセージがある。
# mpiexec --allow-run-as-root --bind-to socket -np 2 python /opt/tensorflow/nvidia-examples/cnn/resnet.py --layers=50 --precision=fp16 --batch_size=128
--------------------------------------------------------------------------
WARNING: Open MPI tried to bind a process but failed. This is a
warning only; your job will continue, though performance may
be degraded.
Local host: 2bbf45ca6ffc
Application name: /usr/bin/python
Error message: failed to bind memory
Location: rtc_hwloc.c:445
--------------------------------------------------------------------------
PY 3.5.2 (default, Nov 12 2018, 13:43:14)
[GCC 5.4.0 20160609]
TF 1.13.0-rc0
PY 3.5.2 (default, Nov 12 2018, 13:43:14)
[GCC 5.4.0 20160609]
TF 1.13.0-rc0
Script arguments:
--predict False
--batch_size 128
--display_every 10
--iter_unit epoch
--num_iter 90
--layers 50
--precision fp16
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmpr7czshlr
Training
WARNING:tensorflow:Using temporary folder as model directory: /tmp/tmpkt9_9irw
Training
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow_estimator/python/estimator/util.py:104: DatasetV1.make_initializable_iterator (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `for ... in dataset:` to iterate over a dataset. If using `tf.estimator`, return the `Dataset` object directly from your input function. As a last resort, you can use `tf.compat.v1.data.make_initializable_iterator(dataset)`.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow_estimator/python/estimator/util.py:104: DatasetV1.make_initializable_iterator (from tensorflow.python.data.ops.dataset_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use `for ... in dataset:` to iterate over a dataset. If using `tf.estimator`, return the `Dataset` object directly from your input function. As a last resort, you can use `tf.compat.v1.data.make_initializable_iterator(dataset)`.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/builder.py:25: conv2d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.conv2d instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/builder.py:25: conv2d (from tensorflow.python.layers.convolutional) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.conv2d instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/builder.py:58: max_pooling2d (from tensorflow.python.layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.max_pooling2d instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/builder.py:58: max_pooling2d (from tensorflow.python.layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.max_pooling2d instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/builder.py:90: average_pooling2d (from tensorflow.python.layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.average_pooling2d instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/runner.py:116: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/losses/losses_impl.py:209: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/builder.py:90: average_pooling2d (from tensorflow.python.layers.pooling) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.average_pooling2d instead.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/cnn/nvutils/runner.py:116: dense (from tensorflow.python.layers.core) is deprecated and will be removed in a future version.
Instructions for updating:
Use keras.layers.dense instead.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/losses/losses_impl.py:209: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/learning_rate_decay_v2.py:321: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Deprecated in favor of operator or tf.math.divide.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/learning_rate_decay_v2.py:321: div (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Deprecated in favor of operator or tf.math.divide.
[2bbf45ca6ffc:00059] 1 more process has sent help message help-orte-odls-default.txt / memory not bound
[2bbf45ca6ffc:00059] Set MCA parameter "orte_base_help_aggregate" to 0 to see all help / error messages
2020-09-14 02:02:10.195593: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3000000000 Hz
2020-09-14 02:02:10.195972: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0xaeb5b70 executing computations on platform Host. Devices:
2020-09-14 02:02:10.195991: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): ,
2020-09-14 02:02:10.277787: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3000000000 Hz
2020-09-14 02:02:10.278051: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0xa411b20 executing computations on platform Host. Devices:
2020-09-14 02:02:10.278067: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): ,
2020-09-14 02:02:10.281113: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-14 02:02:10.282426: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0xac01180 executing computations on platform CUDA. Devices:
2020-09-14 02:02:10.282441: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): GeForce RTX 2070 SUPER, Compute Capability 7.5
2020-09-14 02:02:10.282596: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: GeForce RTX 2070 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.815
pciBusID: 0000:01:00.0
totalMemory: 7.79GiB freeMemory: 7.42GiB
2020-09-14 02:02:10.282623: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0
2020-09-14 02:02:10.366559: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-14 02:02:10.367156: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0x967ba80 executing computations on platform CUDA. Devices:
2020-09-14 02:02:10.367176: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): GeForce RTX 2070 SUPER, Compute Capability 7.5
2020-09-14 02:02:10.367271: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: GeForce RTX 2070 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.815
pciBusID: 0000:02:00.0
totalMemory: 7.79GiB freeMemory: 7.69GiB
2020-09-14 02:02:10.367283: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 1
2020-09-14 02:02:10.559057: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-14 02:02:10.559086: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0
2020-09-14 02:02:10.559092: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N
2020-09-14 02:02:10.559208: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5582 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-09-14 02:02:10.603602: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-14 02:02:10.603630: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 1
2020-09-14 02:02:10.603636: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 1: N
2020-09-14 02:02:10.603764: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 5587 MB memory) -> physical GPU (device: 1, name: GeForce RTX 2070 SUPER, pci bus id: 0000:02:00.0, compute capability: 7.5)
Step Epoch Img/sec Loss LR
2020-09-14 02:02:19.418561: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally
2020-09-14 02:02:19.491472: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally
2020-09-14 02:02:21.279530: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.92GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.279570: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.92GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.414634: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.92GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.414693: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.92GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.617778: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.617829: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.685731: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.685779: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.714468: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 649.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.714498: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 649.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.722806: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.722857: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.743530: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 649.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.743554: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 649.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.753277: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.753299: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 865.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.802270: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.92GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.802343: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 2.92GiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.822577: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 729.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
2020-09-14 02:02:21.822607: W tensorflow/core/common_runtime/bfc_allocator.cc:211] Allocator (GPU_0_bfc) ran out of memory trying to allocate 729.00MiB. The caller indicates that this is not a failure, but may mean that there could be performance gains if more memory were available.
1 1.0 32.3 7.525 8.496 2.00000
10 10.0 228.8 4.313 5.286 1.62000
20 20.0 647.2 0.048 1.025 1.24469
30 30.0 683.5 0.003 0.982 0.91877
40 40.0 672.6 0.023 1.002 0.64222
50 50.0 665.2 0.112 1.092 0.41506
60 60.0 676.2 0.087 1.068 0.23728
70 70.0 665.4 0.082 1.064 0.10889
80 80.0 677.2 0.001 0.983 0.02988
90 90.0 574.4 0.000 0.983 0.00025 上手くいったのだろうか?毎秒670イメージというのは、先にあげたサイトからすると、それらしい値ではないだろうか。でもデータはどこにあるんだ?
同じようなコマンドがここにもあった。しかし LSTM の方は上手く動かせない。
NVIDIA GPU Cloud(NGC)に登録した。必要だったのかな?
(20200915)
2 x RTX2070 Super with NVLINK TensorFlow Performance Comparison では Big-LSTM のベンチマークもある。これを動かしてみる。docker イメージは 19.02-py3 である。
docker run --runtime=nvidia --rm -it -v $HOME/projects:/projects nvcr.io/nvidia/tensorflow:19.02-py3/opt/tensorflow/nvidia-examples/big_lstm にコードがある。最初にデータの用意である。download_1b_words_data.sh を実行する。そうすると、同じフォルダー内に1-billion-word-language-modeling-benchmark-r13output というフォルダーが作成される。この中にデータがあるのだが、これを projects フォルダーに移動させた。この他に、log 用のフォルダーを、これも projects に用意した。これに合わせて、コマンドを下記のように修正した。
python single_lm_train.py --mode=train --logdir=/projects/logs --num_gpus=2 --datadir=/projects/1-billion-word-language-modeling-benchmark-r13output --hpconfig run_profiler=False,max_time=240,num_steps=20,num_shards=8,num_layers=2, learning_rate=0.2,max_grad_norm=1,keep_prob=0.9,emb_size=1024,projected_size=1024, state_size=8192,num_sampled=8192,batch_size=448実行結果を下記に記す。
root@c35a8402c135:/opt/tensorflow/nvidia-examples/big_lstm# python single_lm_train.py --mode=train --logdir=/projects/logs --num_gpus=2 --datadir=/projects/1-billion-word-language-modeling-benchmark-r13output --hpconfig run_profiler=False,max_time=240,num_steps=20,num_shards=8,num_layers=2, learning_rate=0.2,max_grad_norm=1,keep_prob=0.9,emb_size=1024,projected_size=1024, state_size=8192,num_sampled=8192,batch_size=448
WARNING: The TensorFlow contrib module will not be included in TensorFlow 2.0.
For more information, please see:
* https://github.com/tensorflow/community/blob/master/rfcs/20180907-contrib-sunset.md
* https://github.com/tensorflow/addons
If you depend on functionality not listed there, please file an issue.
*****HYPER PARAMETERS*****
{'emb_size': 512, 'num_delayed_steps': 150, 'max_grad_norm': 10.0, 'learning_rate': 0.2, 'vocab_size': 793470, 'batch_size': 128, 'num_gpus': 2, 'keep_prob': 0.9, 'average_params': True, 'num_shards': 8, 'num_steps': 20, 'state_size': 2048, 'max_time': 240, 'run_profiler': False, 'num_layers': 2, 'optimizer': 0, 'do_summaries': False, 'projected_size': 512, 'num_sampled': 8192}
**************************
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/framework/op_def_library.py:263: colocate_with (from tensorflow.python.framework.ops) is deprecated and will be removed in a future version.
Instructions for updating:
Colocations handled automatically by placer.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/big_lstm/model_utils.py:33: UniformUnitScaling.__init__ (from tensorflow.python.ops.init_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.initializers.variance_scaling instead with distribution=uniform to get equivalent behavior.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/big_lstm/language_model.py:75: calling dropout (from tensorflow.python.ops.nn_ops) with keep_prob is deprecated and will be removed in a future version.
Instructions for updating:
Please use `rate` instead of `keep_prob`. Rate should be set to `rate = 1 - keep_prob`.
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/big_lstm/language_model.py:107: to_float (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/nn_impl.py:1444: sparse_to_dense (from tensorflow.python.ops.sparse_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Create a `tf.sparse.SparseTensor` and use `tf.sparse.to_dense` instead.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/ops/array_grad.py:425: to_int32 (from tensorflow.python.ops.math_ops) is deprecated and will be removed in a future version.
Instructions for updating:
Use tf.cast instead.
Current time: 1600138841.891555
ALL VARIABLES
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/big_lstm/run_utils.py:18: all_variables (from tensorflow.python.ops.variables) is deprecated and will be removed after 2017-03-02.
Instructions for updating:
Please use tf.global_variables instead.
model/emb_0:0 (99184, 512) /gpu:0
model/emb_1:0 (99184, 512) /gpu:0
model/emb_2:0 (99184, 512) /gpu:0
model/emb_3:0 (99184, 512) /gpu:0
model/emb_4:0 (99184, 512) /gpu:0
model/emb_5:0 (99184, 512) /gpu:0
model/emb_6:0 (99184, 512) /gpu:0
model/emb_7:0 (99184, 512) /gpu:0
model/lstm_0/LSTMCell/W_0:0 (1024, 8192) /gpu:0
model/lstm_0/LSTMCell/B:0 (8192,) /gpu:0
model/lstm_0/LSTMCell/W_P_0:0 (2048, 512) /gpu:0
model/lstm_1/LSTMCell/W_0:0 (1024, 8192) /gpu:0
model/lstm_1/LSTMCell/B:0 (8192,) /gpu:0
model/lstm_1/LSTMCell/W_P_0:0 (2048, 512) /gpu:0
model/softmax_w_0:0 (99184, 512) /gpu:0
model/softmax_w_1:0 (99184, 512) /gpu:0
model/softmax_w_2:0 (99184, 512) /gpu:0
model/softmax_w_3:0 (99184, 512) /gpu:0
model/softmax_w_4:0 (99184, 512) /gpu:0
model/softmax_w_5:0 (99184, 512) /gpu:0
model/softmax_w_6:0 (99184, 512) /gpu:0
model/softmax_w_7:0 (99184, 512) /gpu:0
model/softmax_b:0 (793470,) /gpu:0
model/global_step:0 ()
model/model/emb_0/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_1/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_2/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_3/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_4/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_5/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_6/Adagrad:0 (99184, 512) /gpu:0
model/model/emb_7/Adagrad:0 (99184, 512) /gpu:0
model/model/lstm_0/LSTMCell/W_0/Adagrad:0 (1024, 8192) /gpu:0
model/model/lstm_0/LSTMCell/B/Adagrad:0 (8192,) /gpu:0
model/model/lstm_0/LSTMCell/W_P_0/Adagrad:0 (2048, 512) /gpu:0
model/model/lstm_1/LSTMCell/W_0/Adagrad:0 (1024, 8192) /gpu:0
model/model/lstm_1/LSTMCell/B/Adagrad:0 (8192,) /gpu:0
model/model/lstm_1/LSTMCell/W_P_0/Adagrad:0 (2048, 512) /gpu:0
model/model/softmax_w_0/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_1/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_2/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_3/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_4/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_5/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_6/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_w_7/Adagrad:0 (99184, 512) /gpu:0
model/model/softmax_b/Adagrad:0 (793470,) /gpu:0
model/model/lstm_0/LSTMCell/W_0/ExponentialMovingAverage:0 (1024, 8192) /gpu:0
model/model/lstm_0/LSTMCell/B/ExponentialMovingAverage:0 (8192,) /gpu:0
model/model/lstm_0/LSTMCell/W_P_0/ExponentialMovingAverage:0 (2048, 512) /gpu:0
model/model/lstm_1/LSTMCell/W_0/ExponentialMovingAverage:0 (1024, 8192) /gpu:0
model/model/lstm_1/LSTMCell/B/ExponentialMovingAverage:0 (8192,) /gpu:0
model/model/lstm_1/LSTMCell/W_P_0/ExponentialMovingAverage:0 (2048, 512) /gpu:0
TRAINABLE VARIABLES
model/emb_0:0 (99184, 512) /gpu:0
model/emb_1:0 (99184, 512) /gpu:0
model/emb_2:0 (99184, 512) /gpu:0
model/emb_3:0 (99184, 512) /gpu:0
model/emb_4:0 (99184, 512) /gpu:0
model/emb_5:0 (99184, 512) /gpu:0
model/emb_6:0 (99184, 512) /gpu:0
model/emb_7:0 (99184, 512) /gpu:0
model/lstm_0/LSTMCell/W_0:0 (1024, 8192) /gpu:0
model/lstm_0/LSTMCell/B:0 (8192,) /gpu:0
model/lstm_0/LSTMCell/W_P_0:0 (2048, 512) /gpu:0
model/lstm_1/LSTMCell/W_0:0 (1024, 8192) /gpu:0
model/lstm_1/LSTMCell/B:0 (8192,) /gpu:0
model/lstm_1/LSTMCell/W_P_0:0 (2048, 512) /gpu:0
model/softmax_w_0:0 (99184, 512) /gpu:0
model/softmax_w_1:0 (99184, 512) /gpu:0
model/softmax_w_2:0 (99184, 512) /gpu:0
model/softmax_w_3:0 (99184, 512) /gpu:0
model/softmax_w_4:0 (99184, 512) /gpu:0
model/softmax_w_5:0 (99184, 512) /gpu:0
model/softmax_w_6:0 (99184, 512) /gpu:0
model/softmax_w_7:0 (99184, 512) /gpu:0
model/softmax_b:0 (793470,) /gpu:0
LOCAL VARIABLES
model/model/state_0_0:0 (128, 2560) /gpu:0
model/model/state_0_1:0 (128, 2560) /gpu:0
model/model_1/state_1_0:0 (128, 2560) /gpu:1
model/model_1/state_1_1:0 (128, 2560) /gpu:1
WARNING:tensorflow:From /opt/tensorflow/nvidia-examples/big_lstm/run_utils.py:32: Supervisor.__init__ (from tensorflow.python.training.supervisor) is deprecated and will be removed in a future version.
Instructions for updating:
Please switch to tf.train.MonitoredTrainingSession
2020-09-15 03:00:42.467627: I tensorflow/core/platform/profile_utils/cpu_utils.cc:94] CPU Frequency: 3000000000 Hz
2020-09-15 03:00:42.468021: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0xe8051e0 executing computations on platform Host. Devices:
2020-09-15 03:00:42.468039: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): ,
2020-09-15 03:00:42.652862: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-15 03:00:42.661208: I tensorflow/stream_executor/cuda/cuda_gpu_executor.cc:998] successful NUMA node read from SysFS had negative value (-1), but there must be at least one NUMA node, so returning NUMA node zero
2020-09-15 03:00:42.661766: I tensorflow/compiler/xla/service/service.cc:161] XLA service 0xbf707d0 executing computations on platform CUDA. Devices:
2020-09-15 03:00:42.661782: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (0): GeForce RTX 2070 SUPER, Compute Capability 7.5
2020-09-15 03:00:42.661788: I tensorflow/compiler/xla/service/service.cc:168] StreamExecutor device (1): GeForce RTX 2070 SUPER, Compute Capability 7.5
2020-09-15 03:00:42.661980: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 0 with properties:
name: GeForce RTX 2070 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.815
pciBusID: 0000:01:00.0
totalMemory: 7.79GiB freeMemory: 7.39GiB
2020-09-15 03:00:42.662025: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1433] Found device 1 with properties:
name: GeForce RTX 2070 SUPER major: 7 minor: 5 memoryClockRate(GHz): 1.815
pciBusID: 0000:02:00.0
totalMemory: 7.79GiB freeMemory: 7.69GiB
2020-09-15 03:00:42.662047: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1512] Adding visible gpu devices: 0, 1
2020-09-15 03:00:43.136398: I tensorflow/core/common_runtime/gpu/gpu_device.cc:984] Device interconnect StreamExecutor with strength 1 edge matrix:
2020-09-15 03:00:43.136431: I tensorflow/core/common_runtime/gpu/gpu_device.cc:990] 0 1
2020-09-15 03:00:43.136437: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 0: N Y
2020-09-15 03:00:43.136441: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1003] 1: Y N
2020-09-15 03:00:43.136529: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:0 with 7097 MB memory) -> physical GPU (device: 0, name: GeForce RTX 2070 SUPER, pci bus id: 0000:01:00.0, compute capability: 7.5)
2020-09-15 03:00:43.136958: I tensorflow/core/common_runtime/gpu/gpu_device.cc:1115] Created TensorFlow device (/job:localhost/replica:0/task:0/device:GPU:1 with 7390 MB memory) -> physical GPU (device: 1, name: GeForce RTX 2070 SUPER, pci bus id: 0000:02:00.0, compute capability: 7.5)
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/saver.py:1266: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file APIs to check for files with this prefix.
WARNING:tensorflow:From /usr/local/lib/python3.5/dist-packages/tensorflow/python/training/saver.py:1070: get_checkpoint_mtimes (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
Instructions for updating:
Use standard file utilities to get mtimes.
Processing file: /projects/1-billion-word-language-modeling-benchmark-r13output/training-monolingual.tokenized.shuffled/news.en-00084-of-00100
Finished processing!
2020-09-15 03:01:01.977579: I tensorflow/stream_executor/dso_loader.cc:152] successfully opened CUDA library libcublas.so.10.0 locally
Iteration 1679, time = 13.12s, wps = 390, train loss = 118.9416
Iteration 1680, time = 9.67s, wps = 529, train loss = 84.3850
Iteration 1681, time = 0.13s, wps = 39567, train loss = 107.0070
Iteration 1682, time = 0.12s, wps = 43874, train loss = 46.1559
Iteration 1683, time = 0.12s, wps = 43468, train loss = 131.2872
Iteration 1684, time = 0.12s, wps = 41286, train loss = 24.5033
Iteration 1685, time = 0.13s, wps = 39113, train loss = 10.7746
Iteration 1686, time = 0.13s, wps = 40528, train loss = 8.6051
Iteration 1687, time = 0.13s, wps = 40463, train loss = 9.6032
Iteration 1698, time = 1.29s, wps = 43670, train loss = 6.2653
Iteration 1718, time = 2.38s, wps = 43072, train loss = 5.7573
Iteration 1738, time = 2.40s, wps = 42656, train loss = 5.4796
Iteration 1758, time = 2.38s, wps = 42996, train loss = 5.5244
Iteration 1778, time = 2.39s, wps = 42835, train loss = 5.2760
Iteration 1798, time = 2.37s, wps = 43159, train loss = 5.3952
Iteration 1818, time = 2.36s, wps = 43388, train loss = 5.3673
Iteration 1838, time = 2.37s, wps = 43276, train loss = 5.1904
Iteration 1858, time = 2.36s, wps = 43450, train loss = 5.2283
Iteration 1878, time = 2.37s, wps = 43183, train loss = 5.2852
Iteration 1898, time = 2.37s, wps = 43123, train loss = 5.1537
Iteration 1918, time = 2.39s, wps = 42910, train loss = 5.1917
Iteration 1938, time = 2.37s, wps = 43116, train loss = 5.1037
Iteration 1958, time = 2.40s, wps = 42714, train loss = 5.1471
Iteration 1978, time = 2.34s, wps = 43729, train loss = 5.1707
Iteration 1998, time = 2.37s, wps = 43210, train loss = 5.1987
Iteration 2018, time = 2.36s, wps = 43455, train loss = 5.2258
Iteration 2038, time = 2.40s, wps = 42578, train loss = 5.1705
Iteration 2058, time = 2.38s, wps = 42976, train loss = 5.1520
Iteration 2078, time = 2.37s, wps = 43233, train loss = 5.1081
Iteration 2098, time = 2.36s, wps = 43329, train loss = 5.0912
Iteration 2118, time = 2.39s, wps = 42915, train loss = 5.0336
Iteration 2138, time = 2.42s, wps = 42392, train loss = 5.1834
Iteration 2158, time = 2.41s, wps = 42498, train loss = 5.1764
Iteration 2178, time = 2.43s, wps = 42054, train loss = 5.0807
Iteration 2198, time = 2.39s, wps = 42920, train loss = 5.0449
Iteration 2218, time = 2.38s, wps = 42971, train loss = 5.1210
Iteration 2238, time = 2.39s, wps = 42810, train loss = 5.0886
Iteration 2258, time = 2.37s, wps = 43293, train loss = 5.0831
Iteration 2278, time = 2.36s, wps = 43421, train loss = 5.0909
Iteration 2298, time = 2.37s, wps = 43118, train loss = 5.0486
Iteration 2318, time = 2.35s, wps = 43585, train loss = 5.0188
Iteration 2338, time = 2.44s, wps = 42022, train loss = 5.0590
Iteration 2358, time = 2.38s, wps = 42990, train loss = 4.9272
Iteration 2378, time = 2.37s, wps = 43289, train loss = 5.0500
Iteration 2398, time = 2.45s, wps = 41724, train loss = 4.9856
Iteration 2418, time = 2.36s, wps = 43446, train loss = 5.0758
Iteration 2438, time = 2.34s, wps = 43741, train loss = 4.9630
Iteration 2458, time = 2.38s, wps = 42944, train loss = 5.0655
Iteration 2478, time = 2.45s, wps = 41783, train loss = 4.9605
Iteration 2498, time = 2.35s, wps = 43632, train loss = 5.0073
Iteration 2518, time = 2.39s, wps = 42790, train loss = 4.9711
Iteration 2538, time = 2.41s, wps = 42567, train loss = 5.0031
Iteration 2558, time = 2.42s, wps = 42400, train loss = 5.0181
Iteration 2578, time = 2.41s, wps = 42504, train loss = 4.9823
Iteration 2598, time = 2.40s, wps = 42630, train loss = 4.9870
Iteration 2618, time = 2.42s, wps = 42401, train loss = 4.9919
Iteration 2638, time = 2.44s, wps = 41888, train loss = 4.8977
Iteration 2658, time = 2.36s, wps = 43455, train loss = 4.9557
Iteration 2678, time = 2.39s, wps = 42842, train loss = 4.9760
Iteration 2698, time = 2.40s, wps = 42700, train loss = 4.9979
Iteration 2718, time = 2.40s, wps = 42586, train loss = 4.9647
Iteration 2738, time = 2.42s, wps = 42345, train loss = 4.9623
Iteration 2758, time = 2.43s, wps = 42118, train loss = 4.9696
Iteration 2778, time = 2.38s, wps = 43028, train loss = 4.9197
Iteration 2798, time = 2.40s, wps = 42663, train loss = 4.9882
Iteration 2818, time = 2.36s, wps = 43447, train loss = 5.0041
Iteration 2838, time = 2.39s, wps = 42926, train loss = 4.9814
Iteration 2858, time = 2.42s, wps = 42396, train loss = 4.8906
Iteration 2878, time = 2.38s, wps = 43072, train loss = 4.9684
Iteration 2898, time = 2.39s, wps = 42780, train loss = 4.8839
Iteration 2918, time = 2.38s, wps = 43013, train loss = 4.9438
Iteration 2938, time = 2.42s, wps = 42382, train loss = 4.9158
Iteration 2958, time = 2.39s, wps = 42872, train loss = 4.8627
Iteration 2978, time = 2.46s, wps = 41696, train loss = 4.9900
Iteration 2998, time = 2.41s, wps = 42408, train loss = 4.9702
Iteration 3018, time = 2.38s, wps = 42959, train loss = 4.9032
Iteration 3038, time = 2.40s, wps = 42754, train loss = 4.9259
Iteration 3058, time = 2.43s, wps = 42223, train loss = 4.8369
Iteration 3078, time = 2.41s, wps = 42545, train loss = 4.8835
Iteration 3098, time = 2.39s, wps = 42882, train loss = 4.9040
Iteration 3118, time = 2.38s, wps = 42957, train loss = 4.8566
Iteration 3138, time = 2.36s, wps = 43320, train loss = 4.8393
Iteration 3158, time = 2.40s, wps = 42588, train loss = 4.8855
Iteration 3178, time = 2.40s, wps = 42647, train loss = 4.8611
Iteration 3198, time = 2.36s, wps = 43448, train loss = 4.9116
Iteration 3218, time = 2.39s, wps = 42789, train loss = 4.8257
Iteration 3238, time = 2.41s, wps = 42556, train loss = 4.8717
Iteration 3258, time = 2.38s, wps = 42967, train loss = 4.8063
Processing file: /projects/1-billion-word-language-modeling-benchmark-r13output/training-monolingual.tokenized.shuffled/news.en-00096-of-00100
Finished processing!
Iteration 3278, time = 4.03s, wps = 25391, train loss = 4.8513
Iteration 3298, time = 2.41s, wps = 42489, train loss = 4.7685
Iteration 3318, time = 2.40s, wps = 42735, train loss = 4.8255
Iteration 3338, time = 2.38s, wps = 43092, train loss = 4.8143
Iteration 3358, time = 2.37s, wps = 43154, train loss = 4.8304
Iteration 3378, time = 2.42s, wps = 42307, train loss = 4.8739
Iteration 3398, time = 2.40s, wps = 42619, train loss = 4.7210
Iteration 3418, time = 2.41s, wps = 42414, train loss = 4.8176
/usr/local/lib/python3.5/dist-packages/tensorflow/python/summary/writer/writer.py:386: UserWarning: Attempting to use a closed FileWriter. The operation will be a noop unless the FileWriter is explicitly reopened.
warnings.warn("Attempting to use a closed FileWriter. " 何を何と比べるべきか良くわからない。上手くいっているのか?温度等をモニターしたものが下記のグラフです。
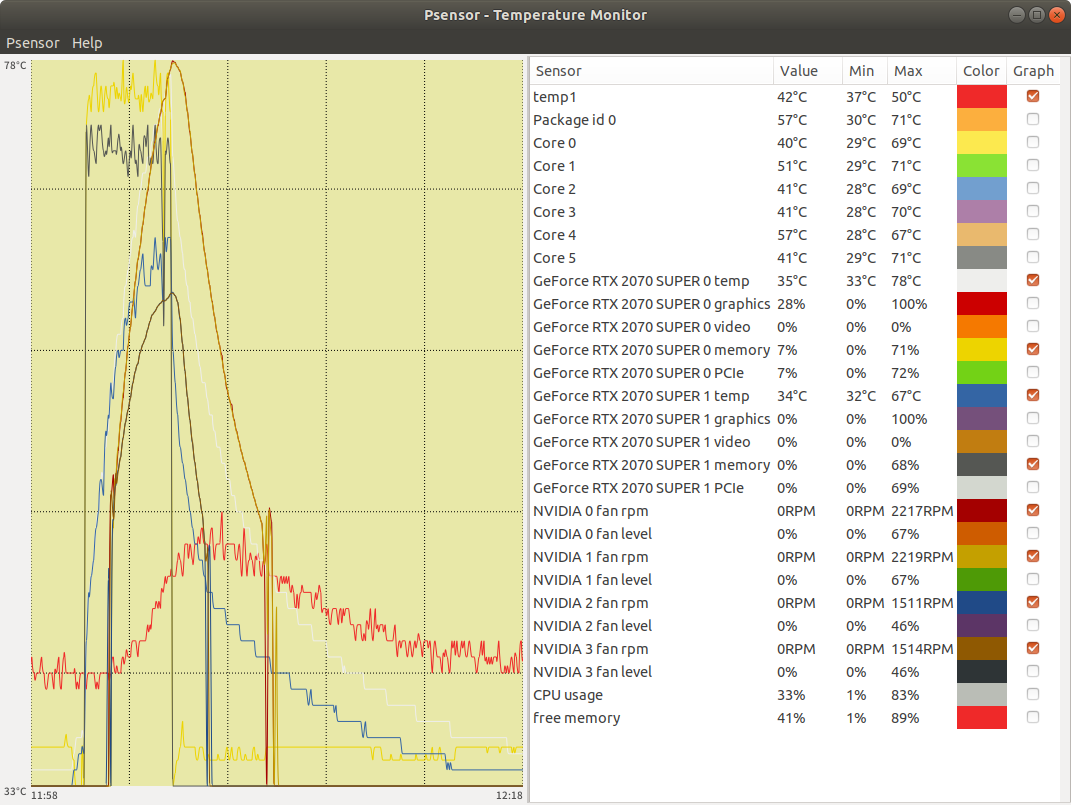
最も早く立ち上がっていて立ち下がっている黒と黄の線がグラフィックカードのメモリー使用率です。この立ち下がっているあたりが計算終了時刻だと思います。急激に立ち上がりだらだらと下がっている青と白の線が温度。温度から遅れて急激に立ち上がって、ストンと落ちている茶と黒の線がファンの回転数です。赤の線はケース内のどこかの温度です。
一応ここで一区切りとして、しばらく tensorflow の本読みでもしようかと思います。