SCORMコンテンツ作成ツールを更新しました。先の記事からあまり時間が経っていないのですが,先の記事に書いた内容も含めて,今回改修したことをあげてみます。
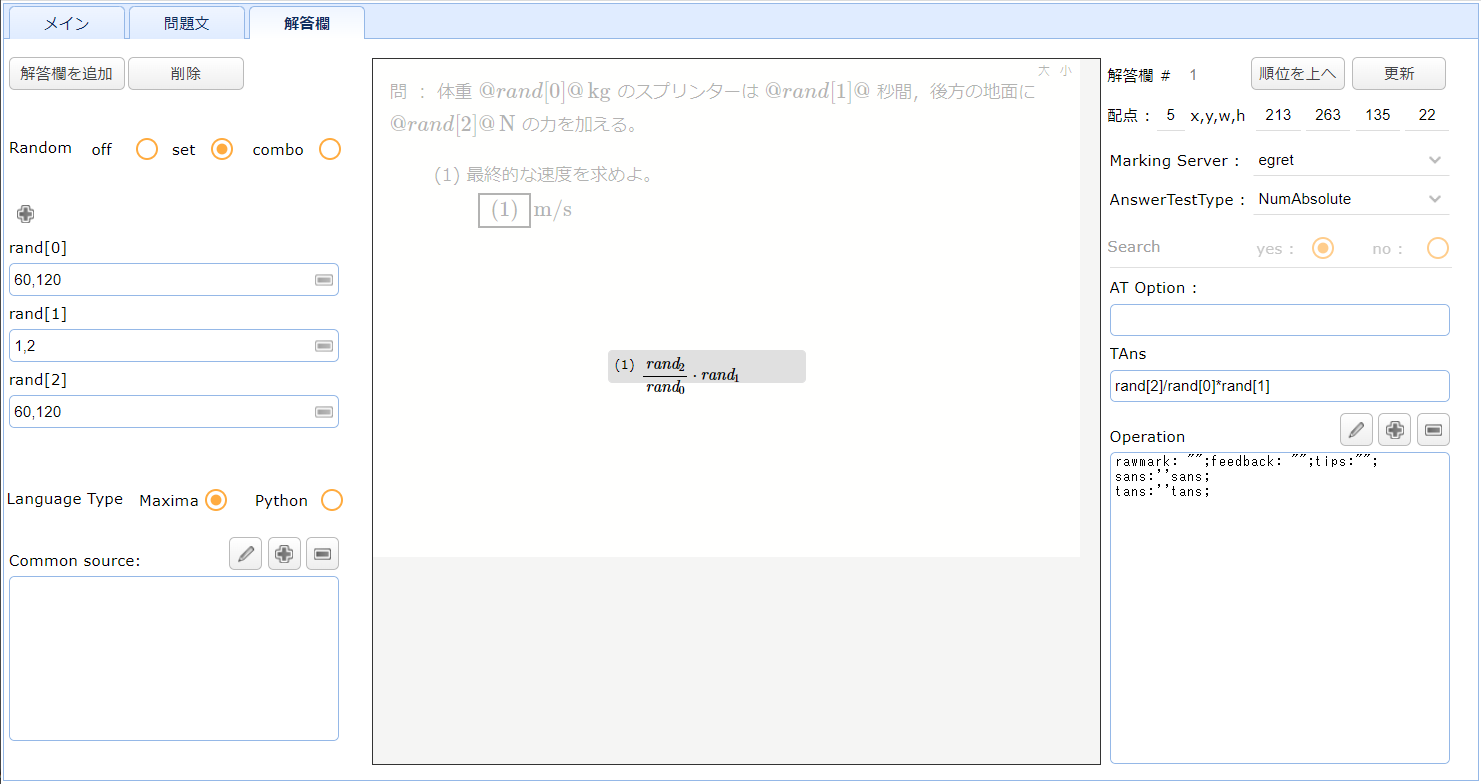
(先にも書きましたが)ひとつは,乱数的な要素を取り入れました。正解を乱数値を用いて表せるようになりました。乱数値には(まだ試していませんが)文字列を利用できると思います。それはどんなコンテンツになるのか?下図はコンテンツ作成用のアプリの画面です。左側に乱数値を設定する欄があります。
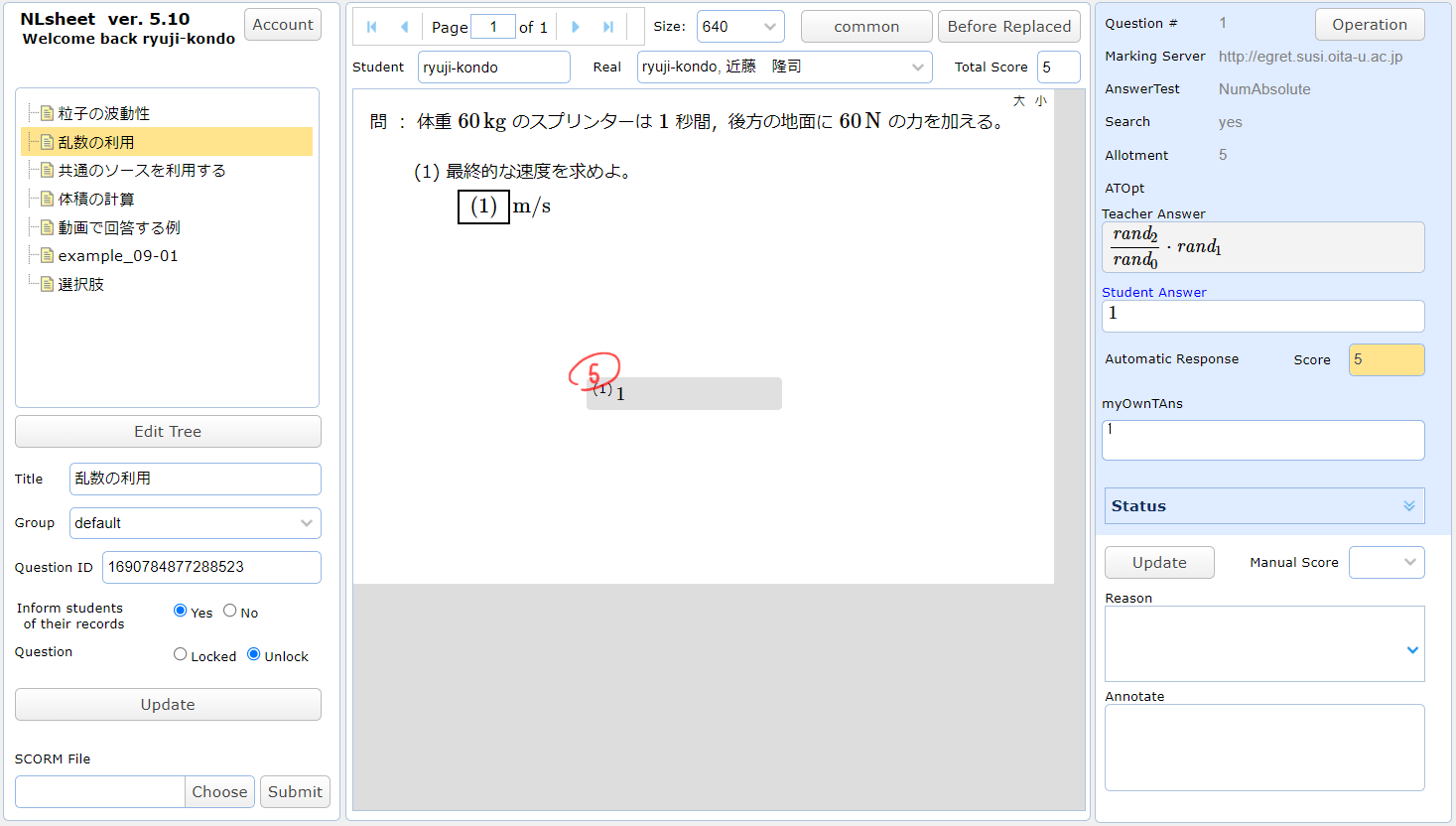
採点用ツールもあわせて乱数値に対応したものになっています。下図は,ひとりひとりの回答を表示して採点するツールです(NLsheet)。正解(Teacher Answer)は乱数値を用いて表されています。真ん中の問題文では,それぞれの受講者に合わせて文中の乱数値が置きかえられています。この問題文が受講者の見るものです。myOwnTAns はこの受講者の場合の正解です。
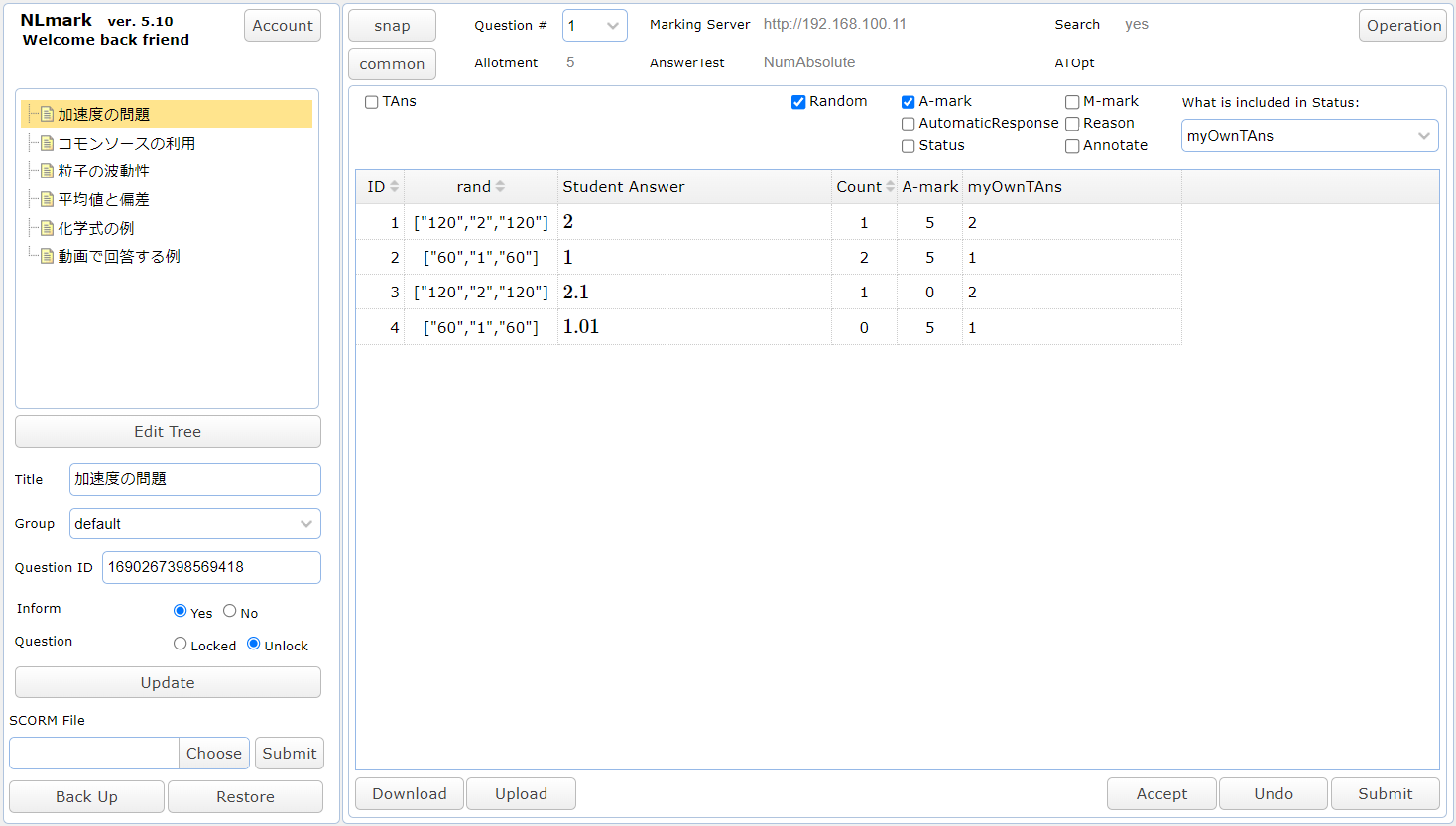
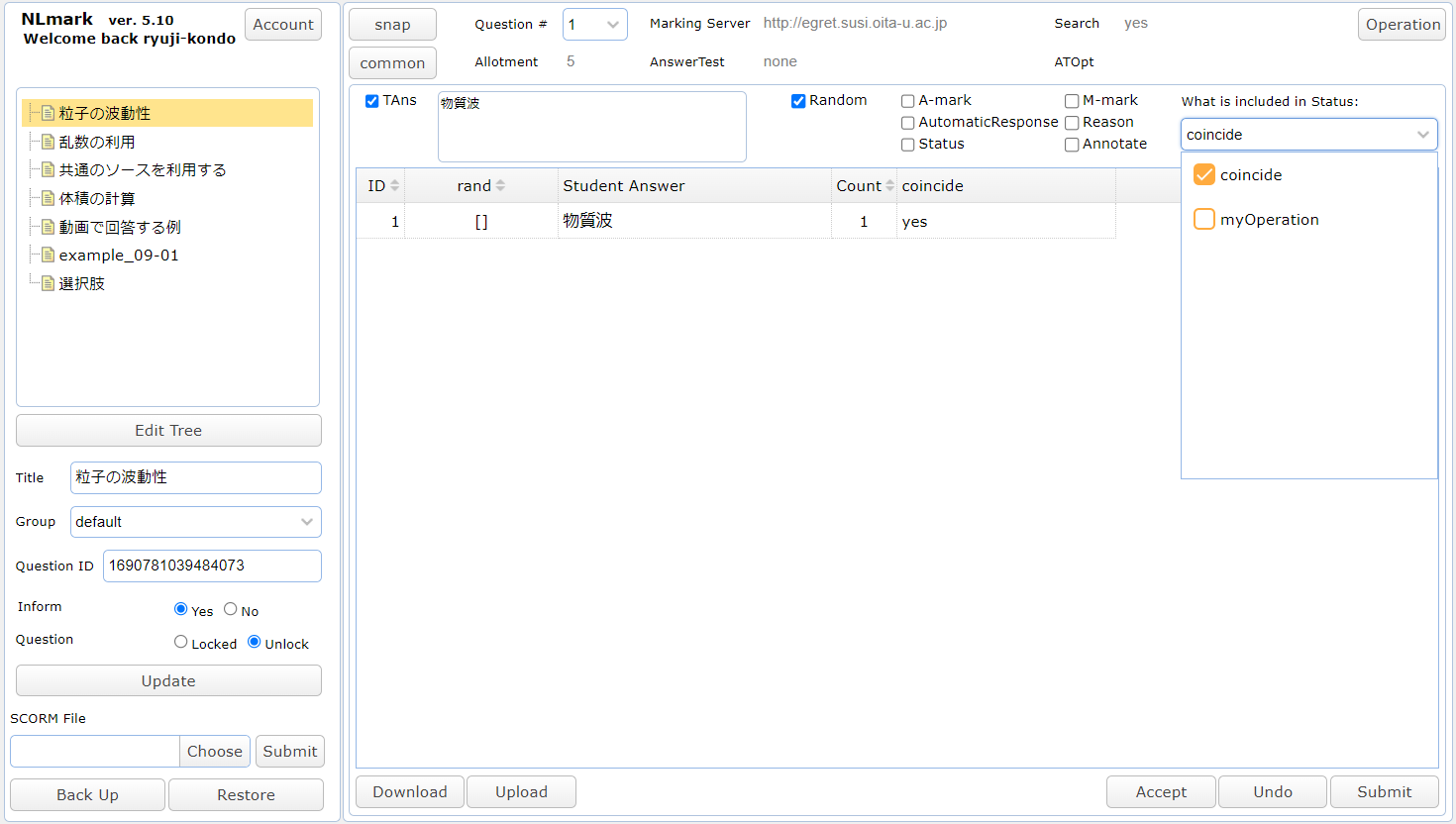
もうひとつの採点ツール(NLmark)のキャプチャーを下記にあげます。これはまとめて採点するツールで,乱数値と回答内容の両方が同じであれば,まとめられて表示されます。count の値が同じ回答をした人数を表しています。A-mark は自動採点の結果です。その乱数値の組合わせの場合の正解が,myOwnTAns に表示されています。
自動採点であっても,まずはデーターベースに記録した過去の採点履歴を検索します。回答のみを検索するのではなくて乱数値の値もあわせたアンド検索です。
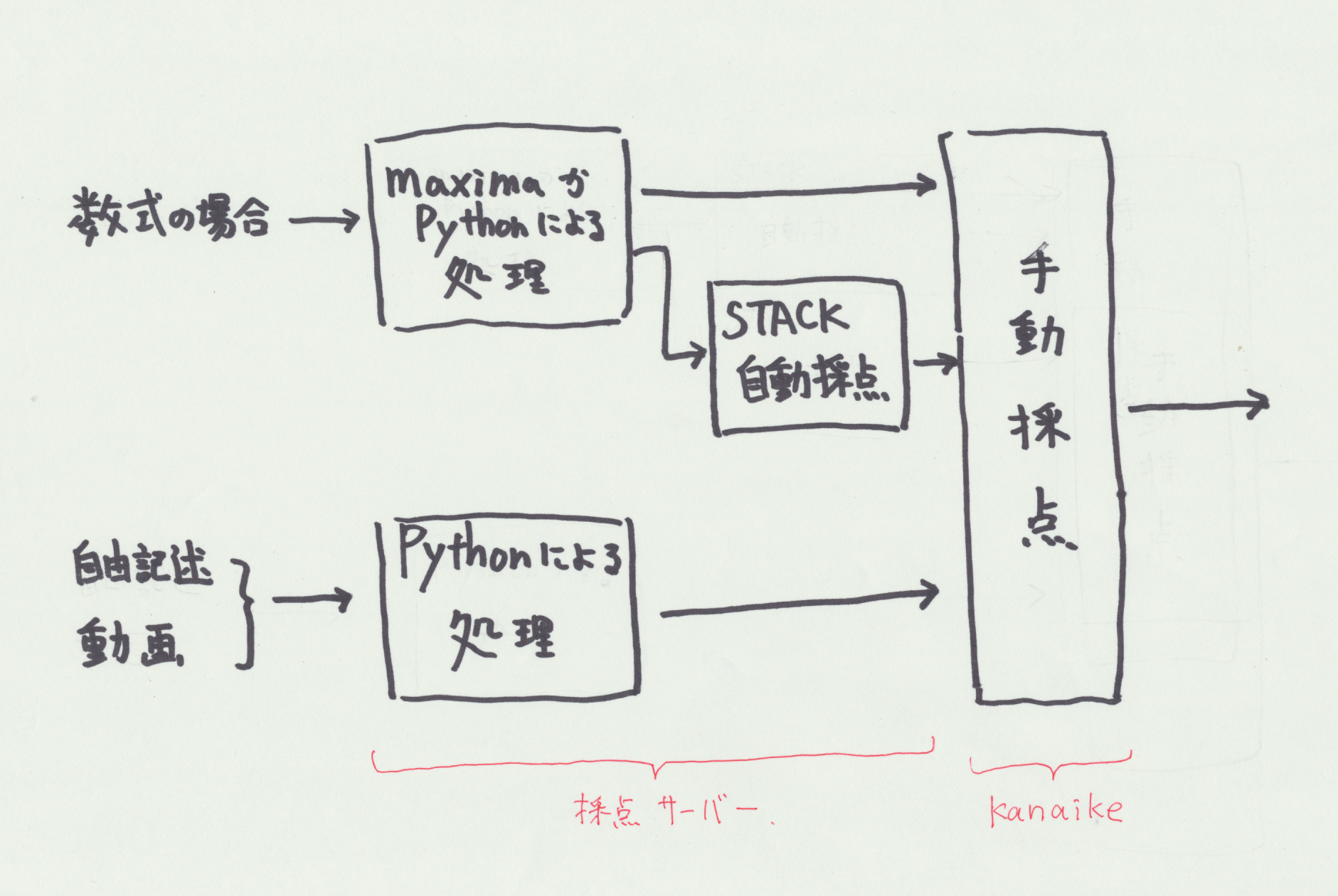
他には,プログラミング的な要素を増やしました。以前から,学生の回答などを Maxima で処理をしたりしていたのですが,これに加えて Python を利用できるようになりました。学生に返すメッセージなどもプログラムから作成できます。採点処理の流れを下図に書きました。コンテンツは数式自動採点と手動採点を合わせたものなのですが,手動採点の前のプログラミング的な要素を拡大しました。詳しくはこちらを参照ください。リンク先はコンテンツ作成用のマニュアルです。
Python を利用する場合には,受講生の回答を調査して何らかの特徴を抽出し,それを採点ツールに反映させ表示することが可能となっています。具体的には status という辞書変数に key と 値を設定すれば,それが採点ツールに現れます。下図では status に,coincide と myOperation という key が設定されていて,そのうちの coincide の値をグリッドに表示しています。この回答から抽出した情報の表示方法が version 5.00 から変化したところです。
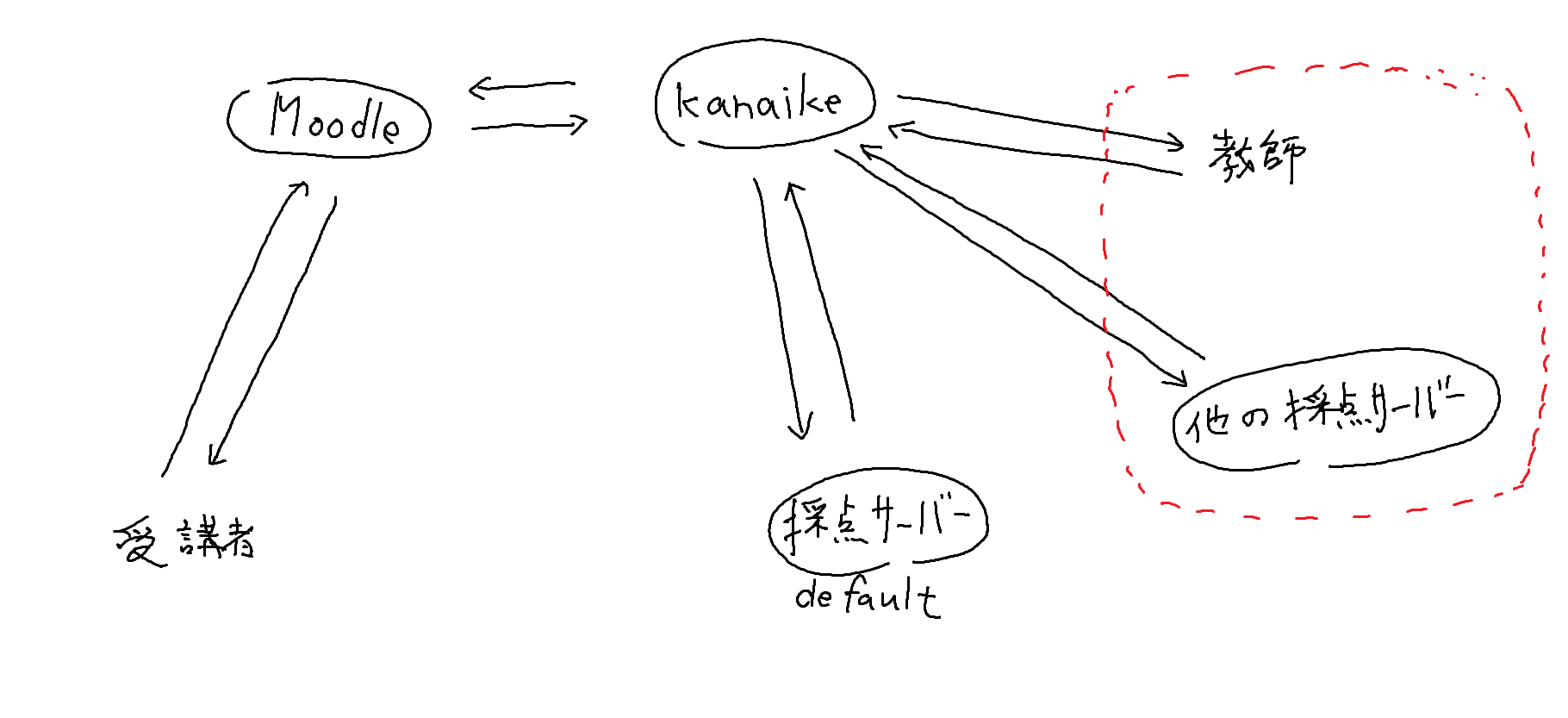
他には,採点サーバーの分離があります。これまでは一台のサーバーが採点とデータベースへの記録等すべてを担っていたのですが,今回採点の部分を別のサーバーとして分離しました。この目的は教師が自由に新しい採点方法を試すことができるように,教師の近くのサーバーで教師自身がフルコントロール可能なパソコンに採点を返すためです。今回 Python を使った処理が可能となったのですが,機械学習等で学習した重みなどを利用するには,自分ですべてを制御できるサーバーの方がやりやすいと思います。新しい採点方法を試みるのに,いちいち他人の許可が要るようではなかなか進まないと思いますので,採点を分離してネットワークリクエストとしました。開発に用いた採点サーバーでは apache が動いていて,他は PHP と WSGI ぐらいです。node.js で作成した方が容易かもしれませんが,自分になじみのある apache を利用して作成しました(参照サイト)。開発に使用している採点サーバーは virtualbox 上の仮想サーバーです。独自の採点サーバーを立てる際には,参考として,この仮想イメージを提供します。
今後は,数式自動採点の際の,汎用的なヒントの仕組みを作成してみたいと考えています。
再掲もありますが,詳しい説明の代わりにヘルプへのリンクをあげます。